前言
介绍
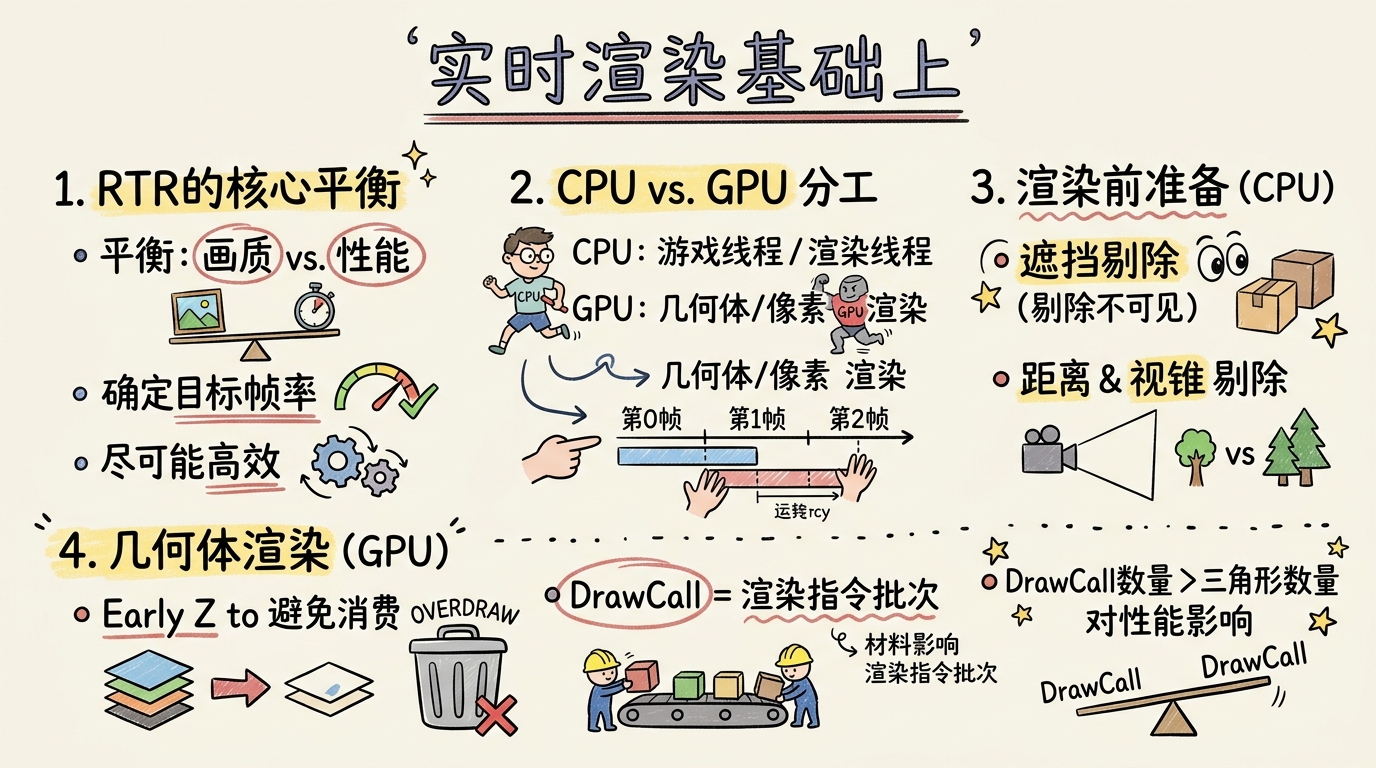
实时渲染在不渲染任何物体的时候能达到其最高性能;
RTR流程的本质是管理性能损耗和画面质量的平衡。
如果画质不提升但是对性能消耗很大,那么这一步就该省略掉
- 确定目标帧率
- 专注于方案和工作流达到目标帧率
- 确保获得尽可能多的回报
实现真实感非常复杂
- 所有环节都必须要尽可能地高效
- 需要严格的流程标准和限制(分辨率
- 将一部分工作分配到预计算环节(空间换时间、烘培
CPU vs GPU
渲染前准备
接下来主要介绍延迟渲染管线,前向渲染可能会带过一点。
线程是同时工作的,在CPU中处理物理、动画等,在第33ms时候CPU处理完成传递给DARWCALL,让其准备一些数据传递给GPU计算,与此同时CPU已经开始第二帧的计算了
CPU 第0帧-0ms-游戏线程
大部分在CPU 第1帧-33ms-渲染线程
遮挡过程(逐物体而不是逐三角形)
建立一个可见物体的列表
- 距离剔除——根据物体与相机的距离决定是否剔除(默认未开启)
- 视锥剔除——根据物体是否在视锥内决定是否剔除
- 预计算可见性——将可见性结果提前计算好并储存下来(空间换时间)
- 遮挡剔除——性能消耗最大,在最后执行
遮挡过程性能提示
几何体渲染
GPU-第2帧-66ms
Prepass/Early Z Pass
GPU现在已经知道了需要渲染的物体的列表及其位置信息,但是如果直接渲染,会有一些像素重复绘制,造成非常大的浪费
因此我们需要找出哪些模块应该先被渲染
- Early Z
DrawCall
Drawcall是指渲染时特定Pass中采用的单一处理过程
通常可以理解为绘制拥有相同属性的一组多边形
切换材质非常影响性能开销
在GPU渲染时,引擎会根据材质对物体进行排序,相同材质的会在同一个批次里绘制
-
Drawcall对性能有非常大的影响
-
每次GPU绘制完成后,需要从渲染线程拿新的指令,这里会有比较大性能开销
-
Drawcall数量对性能的影响比三角形数量要大许多 小Tips:Drawcall的影响比三角形数量对性能的影响要大得多
-
通过stat RHI命令查看运行统计数据
-
2000-3000:合理
-
≥5000:略高
-
≥10000也许会有性能问题
-
移动端在几百左右比较合适
Drawcall相关的性能提示
- Drawcall数量相比多边形数量对性能的影响更大
- 引擎有一些Drawcall的基础开销
- 为了降低Drawcall,我们可以将模型进行合并,但也有副作用
- 一个较为常用的技术称为Modular Meshes
- 也可以使用Instancing降低Drawcall
- Level Of Detail(LOD)和HLOD
Shader
Vertex Shader
顶点着色器性能提示
- 动画越复杂性能越慢
- 定点越多性能越慢
- 高精度的模型最好使用简单的Vertex Shaders
- 对远距离的物体禁用顶点动画
Nanite
一般来说,能启用时应该尽量启用Nanite。虚幻引擎5中的NaniteMesh渲染经过了高度优化,通常可以更快渲染,占用的内存和磁盘空间也更少。
具体而言,网格体如果满足以下条件,将很适合使用Nanite:
- 包含很多三角形,或屏幕上三角形非常小
- 场景中有很多实例
- 作为其他Nanite几何体的主要遮挡物
Nanite目前还不支持:
- 骨骼动画(Skeletal animation)
- 变形目标(Morph Targets)
- 自定义深度或模板
- 半透明材质
- 材质的世界位置偏移(World Position Offset in materials)
- 针对完整Nanite细节的光线追踪
支持的平台
- Nvida:Maxwell显卡或更新版本
- AMD:GCN显卡或更新版本
光栅化和Buffer
提供了变换数据、投影顶点以及必要的着色数据后,下一步时找到了所有在这些三角形内部需要渲染的像素点,这个过程我们称为光栅化
光栅化按照Drawcall的顺序逐次调用