1 矩阵与变换
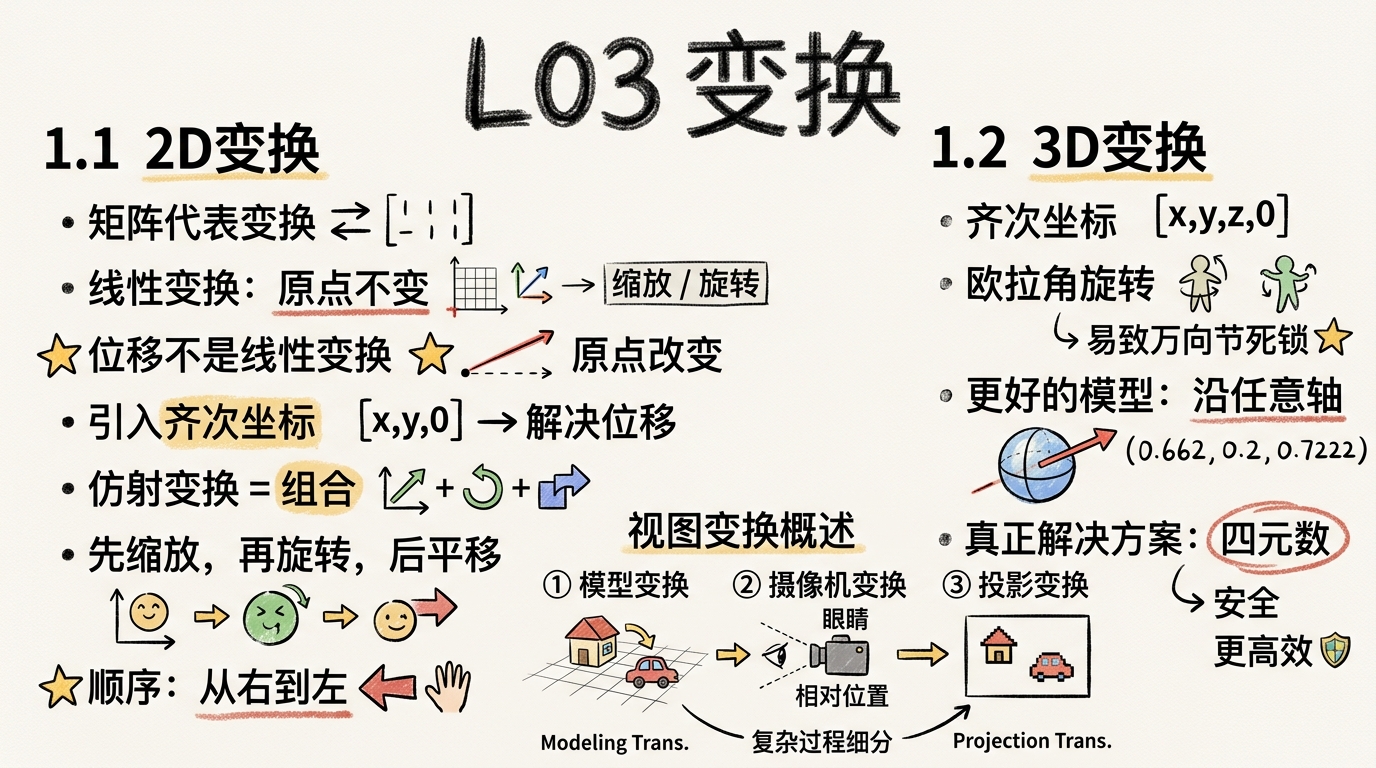
1.1 2D变换
通过线性代数的知识,我们知道 空间的变换可以表示成基的变换,并且最小正交基可以组成单位矩阵
也就是说一个矩阵代表着一个变换,对基的数值变化表现在矩阵的数字上
如下图的可以表示线性代数中的 缩放变换矩阵,旋转变换矩阵
这两种矩阵都可以表示成图右边的这种,矩阵和向量相乘的形式,也就是线性组合形式 所以它们也被叫做是线性变换
但是对于位移变换来说,它的原点改变了 而线性变换是 原点不会改变的变换(保加法和保数乘的性质) 所以位移无法用线性变换表示 (关于这一点,不理解的可以去看 3Blue1Brown的线性代数的本质系列视频)
如果把以上三个变换写成矩阵运算的话
我们在线性变换的形式基础上,只能在后面放个加法来表示位移,这样表示并不方便
这也就是我们引入齐次坐标的原因,因为这样我们可以解决位移带来的问题。
在引入齐次坐标表示向量后,我们可以做到只用一个矩阵来表示2维运动
因为向量因为带有平移不变性,所以齐次坐标中,二维向量的最后一个维度是0这样可以让在齐次坐标中,向量在经过位移变换的计算后,还是它本身。
旋转缩放与平移组合到一起,组合成了仿射变换
仿射变换可以用齐次坐标表示下的矩阵来书写。
复杂的变换可以拆解成简单变换的组合,并且组合的顺序是先缩放,再旋转,后平移,拆解变换的时候就倒过来分析
矩阵乘法没有交换律,所以我们有顺序的要求,从右到左应用变换
1.2 3D变换(欧拉角/万向节锁/四元数)
三维的情况用齐次坐标表示,缩放,旋转,平移, 这里的旋转我们先用欧拉角表示的旋转 (关于欧拉角 在第八节的 欧拉角摄像机 中也有详细描述)
利用旋转矩阵 我们可以把 任意位置向量,沿一个单位旋转轴 进行旋转。
我们也可以将多个矩阵复合,比如先沿着x轴旋转,再沿着y轴旋转。
但是这会很快导致一个问题——万向节死锁(Gimbal Lock,可以看看相关的视频来了解)。
在这里我们不会讨论它的细节,但是对于3D空间中的旋转,一个更好的模型是沿着任意的一个轴,比如单位向量( 0.662 , 0.2 , 0.7222 ) (0.662, 0.2, 0.7222)(0.662,0.2,0.7222)旋转,而不是对一系列旋转矩阵进行复合。
避免万向节死锁的真正解决方案是使用四元数(Quaternion),它不仅更安全,而且计算会更有效率。 关于四元数的理解,我在 入门06 附:关于四元数里进行了比较直观的阐述。
视图变换(Viewing Transformation)
1 摄像机/观察空间概述
我们可以这样来描述视图变换的任务:将虚拟世界中以(x,y,z)为坐标的物体变换到 以一个个像素位置(x,y) 来表示的屏幕坐标系之中(2维),这确实是一个较为复杂的过程,但是整个过程可以被细分为如下几个步骤:
(1) 模型变换(modeling tranformation):这一步的目的是将虚拟世界中或者更具体点,游戏场景中的物体调整至他们应该在的位置
(2) 摄像机变换(camera tranformation):在游戏中我们真正在乎的是摄像机(或者说眼睛)所看到的东西,也就是需要得到物体与摄像机的相对位置
(3) 投影变换(projection tranformation):在摄像机变换之后,我们得到了所有可视范围内的物体相对于摄像机的相对位置坐标(x,y,z),之后根据具体情况选择平行投影或是透视投影,将三维空间投影至标准二维平面([-1,1]^2)之上 (tips:这里的z并没有丢掉,为了之后的遮挡关系检测)
(4) 视口变换(viewport transformation):将处于标准平面映射到屏幕分辨率范围之内,即**[-1,1]^2→[0,width][0,height]*, 其中width和height指屏幕分辨率大小
有了如上4个步骤之后,整个视图变换的过程就变的清晰了起来,如下给出一个具体例子帮助理解:
1.1 View/Camera(视图) Transformation
首先我们需要定义好Camera:
- 设置好相机的位置
- 设置好相机看向的方向,即look-at / gaze direction
- 我们除了相机指向的方向我们还要设置一个up-direction,因为我们需要从不同角度看向场景,就像你拿着手机倾斜45度或者反着拍,最后的照片是不一样的。 至此我们通过一个点,两个向量将相机给固定下来了
我们知道,当相机和物体没有进行相对运动时,不论怎么移动二者,我们看到的结果是一样的。
因此我们将相机始从原来位置移动到原点位置,使得其gaze direction看向-z方向,up-direction是y正半轴。相机移动后,物体/场景跟着相机进行相同的移动,这样虽然进行了移动,但二者最后得到的结果是相同的。
这样做是因为可以简化很多操作,相机在(0,0,0)位置有很多的好处。
假设我们现在有一个相机,在e点上,gaze direction是向量g,up direction是t,我们要把点e给变成原点,向量g在-z轴上,t在y正半轴上。
其基本思想是:
1.进行平移,将e点移到原点。
2.旋转g到-z方向上。
3.旋转t到+y方向上。
4.旋转 g 叉乘 t 得到的向量到+x方向上。
由于我们说过一般是先进行线性变换再进行平移的,但在这里是先平移再线性变换,所以我们将T写在最右边。
平移矩阵很好写,如图所示,难的是我们如何将g, t ,g\times x给旋转到x,y,-z上,这个很难写,但是我们反过来想,我们知道g, t ,g\times x是如何用(x,y,z)表示的,我们只需要求出x,y,-z旋转到g, t ,g\times x
的旋转矩阵,再加上我们知道旋转矩阵的逆矩阵 是这个旋转矩阵的转置矩阵,根据这一性质巧妙的求出了g, t ,g\times x给旋转到x,y,-z上的旋转矩阵。
视图变换View Transform主要有下面两个作用。
- 移动camera,使其位于world space的坐标原点,同样的将其余场景也进行相同的变换使其到应到的位置。
- 旋转camera,使其朝向z轴正方向,也就是视线由原点指向z轴负方向。
1.2 Projection Transformation
- Orthographic projection (正交投影) :多用于工程制图
- Perspective projection(透视投影):符合人眼的成像,会产生近大远小的效果,看起来平行线不会平行,延长的话会相交。 如图,就可以看作是透视投影的结果,鸽子离我们的相机十分近,因此产生了近大远小的效果,使得鸽子比人还要大。
正交投影和透视投影本质的区别就是:是否有近大远小的效果。
正交投影的思想:
1.我们设置camera于原点,看向-Z方向,向上是Y轴
2.然后我们舍弃Z轴也就是让所有物体都Z都等于0,从而我们实现了所有物体只在X轴和Y轴上
3.将其挤压到【-1,1】X 【-1,1】这么一个正方形内.
图形学中的实际操作:
我们定义一个立方体,left,right bottom,top far,near(但是注意我们是看向-Z方向的,far的Z轴值小,near的值大,这就是OPENGL使用左手坐标系的原因)
然后将其的中心平移到原点出,最后将其给拉成一个【-1,1】的正则立方体。
具体的矩阵如图:
透视投影的思想:
1.将Frustum给挤压成一个长方体,也就是将远平面压的和近平面一个大小。
2.做一次正交投影,将长方体的中心移到原点并将其压缩成-1,1的正方体。
注意:
1.在挤压的过程中,近平面永远不会发生变化。
2.在挤压过程中,远平面上的Z值不会发生变化。
3.挤压过程中,远平面的中心点也不会发生变化。
我们知道如何做正交投影,那么接下来来讨论挤压这个Frustum的矩阵如何求。
从图中由两个相似三角形可以得到一个边与边之间的关系: