Compute Shader
一、概念
现在的GPU被设计成可以执行大规模的并行操作,非图形应用使用GPU的情况,如计算数据之类的,我们称之为GPGPU(General Purpose GPU)编程
GPU 会有上千个“核心”,用 NVIDIA 的说法就是 CUDA Core
1.1、Nvidia、AMD
下面学一些概念
SP:最基本的处理单元,streaming processor,也称为 CUDA core。最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理。我们所说的几百核心的 GPU 值指的都是 SP 的数量;
SM:多个 SP 加上其他的一些资源组成一个 streaming multiprocessor。也叫 GPU 大核
核心被组织在流式多处理器(streaming multiprocessor, SM)中,一个线程组运行于一个多处理器(SM)之上。每一个核心同一时间可以运行一个线程
Nvidia :流式多处理器(streaming multiprocessor, SM)是的说法
AMD :Compute Unit
SM 会将它从收到的大线程块,拆分成许多更小的堆,每个堆包含 32 个线程
Nvidia :这样的堆也被称为:**warp,warp 单位共有 32 个线程,称之为:**SIMD-32
NVIDIA 的 SMM架构可以同时运行 4 个以上的 Warp
AMD :则称为**wavefront,**单位则具有 64 个线程,使用 SIMD-16
AMD 的 GCN 架构有 4 个 SIMD-16 单元
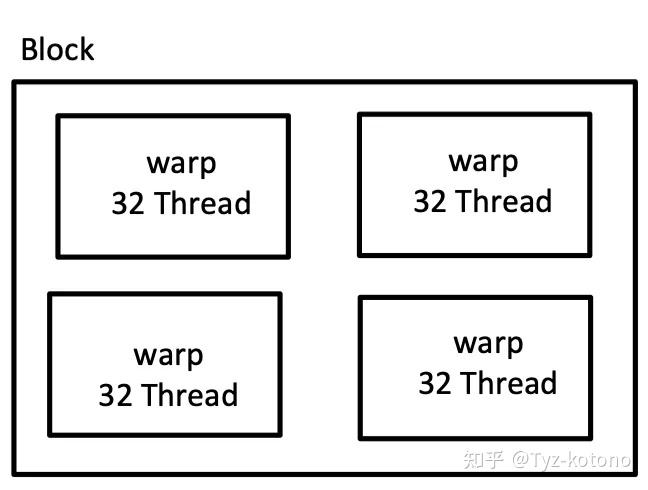
记住 32和64 很关键这是核心数值
每一个线程组都会被划分到一个 Compute Unit 来计算,线程组中的线程由 Compute Unit 中的 SIMD 部分来执行
我们定义 numthreads(8, 8, 1),那么每个线程组就有 8×8×1=64 ,这一整个线程组会被分成1个 warp,调度到单个 SIMD 单元计算
如果是定义 numthreads(8, 8, 2),那么每个线程组就有 8×8×2=128 ,这一整个线程组会被分成2个 warp,调度到两个 SIMD 单元计算。
但是,要获得更佳的性能,我们还应当令每个多处理器至少拥有两个线程组,使它能够切换到不同的线程组进行处理,以连续不停地工作(线程组在运行的过程中可能会发生停顿,例如,着色器在继续执行下一个指令之前会等待纹理的处理结果,此时即可切换至另一个线程组)。
单个 SM 处理逐个 warp,当一个 warp 暂时需要等待数据的时候,就可以先换其他 warp 继续执行
1.2、线程组
线程组的大小应该是多少呢?
线程组的大小设置为warp 尺寸的整数倍。让 SM 同时容纳多个 warp,能够以防一些情况。所以一般我们都会设置线程组为 64的倍数
那么线程组和Computer Shader 有什么关系,经典老图奉上
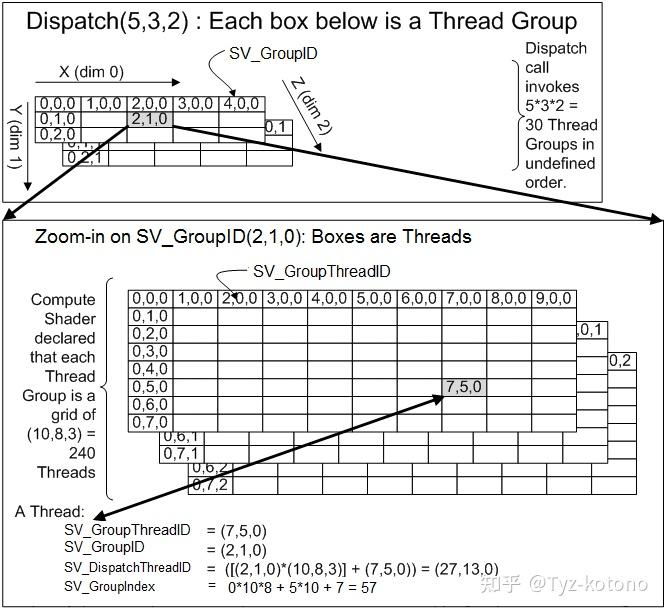
很多原本简单的内容总是被这张图搞得复杂,要理解里面的数学计算原理,以及计算下面四个玩意
SV_GroupID 线程组ID
SV_GroupThreadID 线程组里面线程的ID
SV_DispatchThreadID 线程组内的ID
SV_GroupIndex 线程全局唯一ID
上面四个的计算,一直都是这部分的F和弦,但是我们不用理这四个
Computer Shader 的核心标记只有两个
numthreads [numthreads(x,y,z)]以及Dispatch computeShader.Dispatch(kernel, X, Y, Z);
怎么去理解这两个之间的关系,一个一个来
1.3 numthreads
[numthreads(x,y,z)],我们先不看numthreads
X Y Z我们可以看成三个方向轴,这个我们规定Z为1,即以XY为平面去处理,当然Z设置为其他数值也行,如:2;那就是两个平面叠在一起,拥有两张XY的表格或者两张XY的纸,但是有一个 条件
X * Y * Z = 1024
为了通用,都会建议都以64的倍数线程去执行
不过我们能不能直接以6400W个去跑呢?这是不可能能的,因为实际上线程的数量是有限制的 只有1024个
如果用Computer Shader 处理我们的贴图,如1920 * 1080,这里取下面的满线程组数量,一个Thread只能处理一个像素[numthreads(32,32,1)]
显然 32 x 32 还远远不如我们常用的贴图 64 x 64 大小 ,指望computer Shader去处理数以万计的顶点模型或者贴图似乎不可能了?

可以看到[numthreads(32,32,1)] 的线程处理的1024像素 小黑点只占据了屏幕一小块。那么怎么办呢
1.4 Dispatch
在Unity中,Compute Shader的Dispatch方法的参数有一些限制。这些参数定义了要启动的线程组的数量。每个参数(X,Y,Z)的最大值通常由硬件决定,但通常不会超过65535
我们要怎么利用小黑点把1920 * 1080屏幕占满
1920 / 32 = 60 1080 / 32 = 33.75 向上取整保证占满屏幕 取34
你发现,如果我们要占满屏幕,只需要 60 * 34个**小黑点,**怎么样才能做到搞出60 * 34个小黑点,这个就是Dispatch的作用,我们只需要
computeShader.Dispatch(kernel, 60, 34, 1);
加上下面,这个,我们就可以占满整个屏幕
[numthreads(32,32,1)]
1.5 总结
下面会偷换概念,利用其他词语来解释,并且都会以那些词语来解释
人话解释:
numthreads是一层楼,楼层的面积大小是固定的,最多容纳 1024个学生。
其中你可以有 X组,Y排,Z个教室,这是常见的线程配置
[numthreads(32,32,1)]翻译为:你有1间教室,里面有32组,一组有32个人
[numthreads(16,16,4)]翻译为:你有4间教室,里面有16组,一组有16个人
Dispatch是教育厅
它规定了每次Dispatch,盖几个学校,一个学校有几个教学楼,教学楼有几层
每一层有几个教室我们不关心,我们有规定,一层楼最多坐1024个学生即 1024个thread
分别是教学楼 X栋,Y层,有Z个学校
那么要多少个学校呢?
我们不管,我们只要保证今年录取的学生每个都有座位就行,教室少几个学生也行,有多余空位也没关系
所以写ComputerShader 和我们建学校一样,要保证人人有座位。
要求速度快,就每个学生每科都布置作业,让他们24小时不停写试卷。
如果是考试,有些学霸做题快怎么办
我们规定 12点才能交卷,方便我们统一收卷,收到训导处,利用铃声
GroupMemoryBarrierwithGroupsync();
给我等待其他学生做好试卷,不准提前交卷,但是仅限于针对自己所在的楼层,单独的Group,隔壁层管不到
二、计算
2.1、SV_GroupID
那么问题来了
SV_GroupID 线程组ID
SV_GroupThreadID 线程组里面线程的ID
SV_DispatchThreadID 线程全局唯一ID
SV_GroupIndex 线程组内的ID
这四个怎么理解,怎么计算。有了前面的 numthreads和Dispatch 概念,我们可以很好的理解这一部分怎么去计算
先约定好(X,Y,Z)为X组,Y排,Z个教室
在GPU这个世界,从0开始数,很重要
在GPU这个世界,从0开始数,很重要
在GPU这个世界,从0开始数,很重要
首先,我们要以Thread Group为单位,也就是楼层为单位,毕竟一个楼层只能同时上下课,同一个时间的Thread Group只能执行一个 Warp。
总不能你在上课,隔壁班过来观望吧,所以同一个楼层上课时间一致
其中Group是楼层,那么SV_GroupID 就是你们的楼层编号,如:
SV_GroupID = (2,1,0)
也就是学校的第3个教学楼,第2层
那么是那个学校呢?Z = 0 所以是第1个学校
(index = 0).length = 1
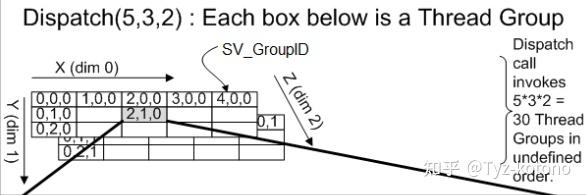
其中旁边的算术 5 x 3 x 2 = 30 指的是所有的楼层数量,即Thread Groups
满楼层矩阵为(5,3,2) = 5 x 3 x 2 = 30
也就是这次Dispatch规划
有2个学校,一个学校有5个教学楼,一个教学楼有3层
2.2、SV_GroupThreadID
我们前面说过Group是楼层,Thread是人,那么GroupThreadID,就是所在班级那个人的座位,是在那个教室那组那列
如:
SV_GroupThreadI = (7,5,0)
就是 第8组 第6个学生,在第一个教室
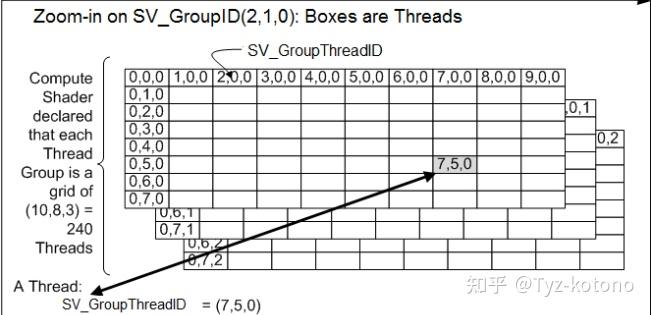
其中旁边的算术 10 x 8 x 3 = 240 指的是班级能够坐满的学生数量,即Thread
楼层满载矩阵(10,8,3) = 10 x 8 x 3 = 240
也就是一个楼层最多有3个教室,一个教师有10组,一组最多有8个人
2.3、SV_GroupIndex
我们先规定第1名到80名在第一件教室,81到160在第二个教室,以此类推
这个怎么理解,很简单。Group是楼层加index ,其实就是你的楼层里面你的排名,那么排名多少?
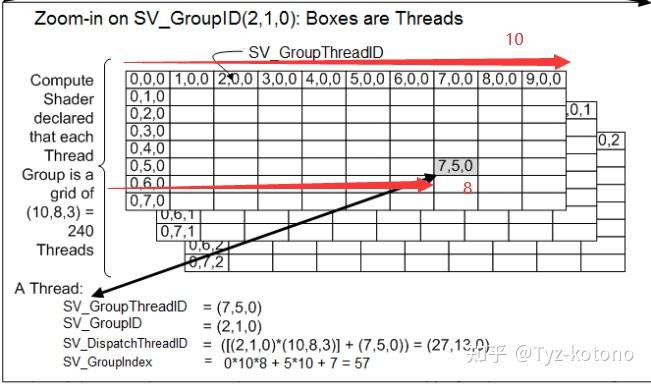
如:还是她SV_GroupThreadI = (7,5,0)
在GPU这个世界,从0开始数,很重要
他的排名是多少,注意我们要从0开始算,
他是第一个教室的第8组 第6个学生,所以他是前面没有教室0 * 10 * 8 = 0
他在第8组 第6个学生,看一下表格,就知道怎么算了,每组都有5个人成绩比他好,然后每组的第六个人排名里,他第八5 * 10 + 8 = 58
再加上其他班级参与排名0 * 10 * 8 + 5 * 10 + 8 = 58
但是我们的排名是从0开始的,所以他是58 -1 = 57名SV_GroupIndex = 57
2.4、SV_DispatchThreadID
这个怎么理解呢,类似于该地区总排名。你的八校联考在市里面的排名,但是为了实际排名太难看,我们用矩阵来表示
Dispatch(5,3,2)
这个地区有2个学校,一个学校有3个教学楼,一个教学楼有5层
一个楼层满载矩阵是(10,8,3) = 240
SV_GroupID = (2,1,0) SV_GroupThreadI = (7,5,0)
我们的学校排名是第1名,然后我们在第3个教学楼的第2层学习
座位是在第1个教室的第7组的第5排
那么换算就是,先计算当前楼层第一名在总排名为多少,然后再计算自己的,最后相加就是自己的排名
当前楼层第一名在总排名
(2,1,0)* (10,8,3) = (20,8,0)
自己的排名
(7,5,0)
自己在这个地区的排名
(20,8,0) + (7,5,0) = (27 , 13 , 0)
其中(27 , 13 , 0) = 27 * 13 = 351
2.5、VRAM
接下来继续说明一些原理类的东西,不会太深入,可以去看看比较官方的文章
显存:(VRAM,Video Random Access Memory),显卡全局内存
当我们知道了上面的那些东西怎么计算以后,就可以开始去使用Computer Shader
如:我们需要让一个线程处理一个mesh 上面的顶点,处理一个图片上的像素,我们都需要获得结果,如果不获得结果,计算了也没用
因此我们需要定义个可以被Computer SHader修改,可以被我们代码读取的容器
RWStructuredBuffer<T> customBuffer;
这里引出了另一个内容,这个Buffer 大小是多少,读写速度区别一样吗?
RWStructuredBuffer定义在全局内存即显存,大小是你显卡上面标示的大小。显存就像一个大图书馆,里面有着我们想要的数据。
但是事实证明住图书馆隔壁的人和隔壁区的人,对于图书馆的访问速度是不一样的。
虽然全局内存可以被所有的GPU核心(或者说线程)访问,但是由于其位于GPU芯片外部(即使是集成在同一块硅片上,也相对于核心的位置较远),因此其访问速度相比于共享内存(如Local Data Share)和寄存器要慢一些。
所以图书馆(VRAM)的人很少,又不能带太多东西搬来搬去麻烦,但是隔壁教师办公室(SM )没收的小说,只要认错就能获取,这才是我们最快方式
[numthreads(16,16,4)]
还记得吗?numthreads和Group 是教学楼第几层的意思?后面要考!
2.6、SM LDS
认错前,要先听教,所以先来一套官方术语:
**Local Data Share(LDS)**是一种共享内存 (Shared Memory),它是在 GPU 中的每个计算单元(Compute Unit,CU)内部存在的一种特殊类型的内存。LDS 可以被同一计算单元内的所有线程(在 GPU 术语中通常称为工作项)访问,因此它可以用于在工作项之间共享数据。
NVIDIA:CUDA 架构中,这种内存被称为共享内存(Shared Memory)
AMD :GPU 架构中,它被称为 Local Data Share 或 LD
即,如果我们想要提快速,那么相比于与访问显存,我们可以直接访问共享内存,速度会更快。
那么为什么不同线程组之间的线程不能直接访问彼此的共享内存
前面我们说了,线程组在自己独立的楼层(Group )里面,访问楼层里面教师办公室,并且教师办公室大小也是固定的,一般单位只有KB
生活小场景
如果对面5楼的同学,要过来访问我这边3楼的教师办公室,实在是太麻烦了,我们不知道楼与楼之间的距离,并且不知道楼层多高,有没有电梯,外面有没有下雨。
通常解法是约定一个地方,大家都去哪里,所以就是图书馆(VRAM),碰头后再回去教室写作业,又是一段路程。
因此如果需要跨线程组共享数据,通常需要使用全局内存(VRAM),但这会带来更高的性能开销。
所以,可以跨线程组,但是没必要!还是声明共享内存比较好
groupshared float sharedMemory[1024];
2.7、Consume
访问类型:
(1)、消耗其实也有讲究,在老师叼人约谈的时候,一个一个叫,其实耗时十分久十分长,教育完一个人,就得让被叼的同学根据哈希(座位号)去叫下一个人过来。这个过程十分漫长
(2)、如果直接叼班干部,班干部再回去叼同学,这样也太麻烦了
(3)、但是如果是直接开班会,一口气骂全班同学,那效率可就不是一点半点了。
所以在使用Computer Shader的时候,要避免这种一次性叼人太少,需要等待的情况,如
(1)碎片化
内存碎片化不连续的,每块共享内存块较小的时候,就会导致更多的缓存未命中。即使用哈希去访问,类似与上面的访问类型(1)
(2)等待
前提知识:“Bank”是指共享内存的一个特定部分,而不是线程。每个Bank可以在一个时钟周期内为一个线程提供一个字的数据。因此,如果一个Warp(32个线程)在一个时钟周期内访问32个不同的Bank,那么所有这些访问可以同时发生,这被称为并行内存访问。
一个 Warp 有 32 个线程,但是共享内存里面只有几个Bank,如,只有16个,warp里面有一般的线程。需要等待另一半的线程访问结束,才能访问共享内存,类似与上面的访问类型(2)
因此建议使用访问类型(3),不会有等待,碎片化的情况。少用哈希访问,多使用内存连续的类型如:Struct、数组、矩阵、向量、字符串
三、范例
3.1、Texture
我们可以先试试采样一张贴图,随后模糊处理
Shader里面,使用一个3x3 的卷积核,Shader需要双Pass,分别处理垂直方向和水平方向,这是比较常见的做法,当然单个Pass也可以。
sampler2D _MainTex;
float4 _MainTex_TexelSize;
float4 HorizontalBlur(float2 uv) {
float4 color = float4(0, 0, 0, 0);
// Left
color += tex2D(_MainTex, uv + float2(-1.0, 0.0) * _MainTex_TexelSize.xy) * 1.0/4.0;
// Center
color += tex2D(_MainTex, uv) * 2.0/4.0;
// Right
color += tex2D(_MainTex, uv + float2(1.0, 0.0) * _MainTex_TexelSize.xy) * 1.0/4.0;
return color;
}
float4 frag(v2f i) : SV_Target {
float2 uv = i.uv;
float4 color = HorizontalBlur(uv);
return color;
}
sampler2D _MainTex;
float4 _MainTex_TexelSize;
float4 VerticalBlur(float2 uv) {
float4 color = float4(0, 0, 0, 0);
// Top
color += tex2D(_MainTex, uv + float2(0.0, -1.0) * _MainTex_TexelSize.xy) * 1.0/4.0;
// Center
color += tex2D(_MainTex, uv) * 2.0/4.0;
// Bottom
color += tex2D(_MainTex, uv + float2(0.0, 1.0) * _MainTex_TexelSize.xy) * 1.0/4.0;
return color;
}
float4 frag(v2f i) : SV_Target {
float2 uv = i.uv;
float4 color = VerticalBlur(uv);
return color;
}
Computer Shader
其实Computer Shader 的做法与上面的Shader内部写Pass并无多大区别,只是Pass成了kernel
Shader 里面是利用UV去采样,那么Computer Shader 如何去采样贴图
前面我们已经知道了,一个numthread可以处理一个像素,那么可以直接使用
uint3 id : SV_DispatchThreadID
float R = inputTexture[id.xy].r;
但是这样偶会会出错,使用的是Texture2D对象的数组操作符[]来读取贴图数据。这种方式会进行贴图过滤。这是为什么?
因为我们如果使用的坐标不是整数,它会根据周围的像素进行插值
3.2、Map filtering
Map filtering (贴图过滤 )这是为啥?会发生这种事
当你分配的学生和像素对不上,会发生一个学生处理多个像素。这个时候就会发生Map filtering 。即会使用三线性插值。这部分有点类似于mipmap取值。
本质都是处理纹理映射时的像素插值问题,一个纹理被映射到一个比它大或者小的多边形上时,就需要进行贴图过滤,通过在纹理的像素之间进行插值来生成新的像素值,以此来改善渲染的质量。这个时候就看你是否需要精准的像素值。
如果需要精准的像素颜色,我们就应该,让一个numthread可以处理一个像素,更为准确的方法应该是
//UV 采样
color = Input.Load(int2(uv , 0)) ;
//UV 偏移
color += Input.Load(int2(uv + float2(-1.0, 0.0) * Input_TexelSize));
这个采样方法是DirectX HLSL的内置函数,用于从纹理中加载数据
知道了上面的信息,我们只需要让学生处理像素的时候,考虑左边同学,右边同学,前桌,后桌,我们就能得到准确的答案,但是这个答案是模糊不清的
#pragma kernel Blur
RWTexture2D<float4> Result;
Texture2D<float> Input;
int2 Input_TexelSize;
[numthreads(16, 16, 1)]
void Blur(uint3 id : SV_DispatchThreadID) {
float2 uv = id.xy;
float4 color = float4(0, 0, 0, 0);
// Horizontal
color += Input.Load(int2(uv + float2(-1.0, 0.0) * Input_TexelSize)) * 1.0/4.0;
color += Input.Load(int2(uv)) * 2.0/4.0;
color += Input.Load(int2(uv + float2(1.0, 0.0) * Input_TexelSize)) * 1.0/4.0;
// Vertical
color += Input.Load(int2(uv + float2(0.0, -1.0) * Input_TexelSize)) * 1.0/4.0;
color += Input.Load(int2(uv)) * 2.0/4.0;
color += Input.Load(int2(uv + float2(0.0, 1.0) * Input_TexelSize)) * 1.0/4.0;
Result[id.xy] = color;
}
其中kernel 是干嘛用的?
#pragma kernel Blur
//说明用
#pragma kernel Play_1
#pragma kernel Play_2
#pragma kernel Play_3
我们可以这么理解,我们的学生有三个计划,开学干嘛,期中干嘛,期末干嘛。这就是我们的kernel ,阶段性计划,要干嘛干嘛,我们每次做事,都得从按照计划中开始执行,不然努力只会事倍功半
[numthreads(16, 16, 1)]
void Play_1(uint3 id : SV_DispatchThreadID) {}
这里可以理解为,我们安排了16 * 16 个学生做 Play_1,然后这个Play_1具体怎么执行?
[numthreads(16, 16, 1)]
void Play_1(uint3 id : SV_DispatchThreadID)
{
funtion_1();
funtion_2();
funtion_3();
}
我们可以funtion_1、funtion_2、funtion_3、去执行
3.3、RW
其实RW贴图不是很好用,会占用更多的带宽,使得优化失效。
1、由于RW贴图允许在shader中进行读写操作,这可能导致多个shader同时访问和修改同一块内存。为了保证数据的一致性,GPU需要在访问和修改数据时进行同步,这会增加额外的开销。
一般建议只读纹理,可以被GPU有效地缓存和压缩,从而减少内存和带宽的使用。
2、GPU通常会对常用的纹理数据进行缓存,以减少内存访问的开销。由于RW贴图可以被修改,GPU无法确定缓存中的数据是否仍然有效,因此可能需要频繁地更新缓存,这会增加带宽的使用。
3.4、Unity
using UnityEngine;
public class BlurEffect : MonoBehaviour
{
public ComputeShader BlurShader; // Compute Shader引用
public Renderer TargetRenderer; // 目标渲染器,我们将把处理后的纹理应用到这个渲染器的材质上
private RenderTexture resultTexture; // 用于存储结果的纹理
private int kernelHandle; // Compute Shader内核句柄
void Start()
{
// 获取内核句柄
kernelHandle = BlurShader.FindKernel("Blur");
// 创建新的渲染纹理
resultTexture = new RenderTexture(Screen.width, Screen.height, 24);
resultTexture.enableRandomWrite = true;
resultTexture.Create();
ExecuteShader(resultTexture);
}
// 调用此方法以执行Compute Shader
public void ExecuteShader(Texture inputTexture)
{
// 设置输入和输出纹理
BlurShader.SetTexture(kernelHandle, "Result", resultTexture);
BlurShader.SetTexture(kernelHandle, "Input", inputTexture);
// 设置输入纹理大小
BlurShader.SetInts("Input_TexelSize", new int[] { inputTexture.width, inputTexture.height });
// 执行Compute Shader
BlurShader.Dispatch(kernelHandle, inputTexture.width / 16, inputTexture.height / 16, 1);
// 创建新的材质并将处理后的纹理应用到这个材质上
Material newMaterial = new Material(TargetRenderer.material.shader);
newMaterial.mainTexture = resultTexture;
// 将新的材质应用到目标渲染器上
TargetRenderer.material = newMaterial;
}
void OnDestroy()
{
// 释放渲染纹理
resultTexture.Release();
}
}
这部分中,我们利用FindKernel知道了学生可以执行那些计划
kernelHandle = BlurShader.FindKernel("Blur");
随后利用Dispatch 告诉学生开始执行计划,计划安排是
BlurShader.Dispatch(kernelHandle, inputTexture.width / 16, inputTexture.height / 16, 1);
执行计划
kernelHandle = BlurShader.FindKernel("Blur");
安排的是, 楼数,层数,学校数量
inputTexture.width / 16, inputTexture.height / 16, 1
最后别忘了学生数量是
[numthreads(16, 16, 1)]
这么多人去执行任务
3.5、差异性
那么问题来了Shader 和Computer Shader,本质都是Shader,GPU中处理信息,有啥区别吗?我们可以区分一下
Shader 多Pass:
Shader多Pass是它通过多次渲染来实现复杂的图形效果。每一次渲染被称为一个Pass,每个Pass都会生成一个中间结果,然后这个结果会被用作下一个Pass的输入。
下面列一下常见的优势、缺点、优化方法
优势:
- 兼容性好:在所有支持图形Shader的硬件上都可以使用,包括较旧的硬件。
- 易于实现复杂效果:通过将复杂的图形效果分解为多个简单的Pass,可以更容易地实现这些效果。比如上面的垂直水平模糊,多Pass法线外扩描边。
缺点:
- 消耗大:多一次Pass就会多一次消耗,多渲染一次流程,包括顶点处理、光栅化、片元处理等。应该尽量减少使用多Pass的情况。
性能优化:
- 减少Pass数量:每个Pass都需要GPU进行一次完整的渲染过程,包括顶点处理、光栅化、片元处理等。因此,减少Pass的数量可以显著提高性能。
- 合并小批量的渲染调用:如果可能,应该尽量合并小批量的渲染调用,以减少CPU和GPU之间的通信开销。
Compute Shader:
优势:
- 更高的灵活性:Compute Shader可以直接访问GPU的并行计算能力,因此它比图形Shader有更高的灵活性。例如,它可以进行随机访问、原子操作等。
- 更高的性能:由于Compute Shader可以直接访问GPU的并行计算能力,因此它通常可以提供更高的性能。
缺点:
- 支持力度不够:现在其实基本默认移动端不支持,所以不让用,不要猜对方用什么设备玩你的游戏!!!!!!!!!!!!!
性能优化:
- 优化内存访问:GPU的性能在很大程度上取决于内存访问的效率。因此,应该尽量优化内存访问,例如通过使用共享内存、减少全局内存访问等。
- 优化线程组大小:线程组的大小会影响GPU的并行计算效率。因此,应该根据具体的硬件和算法来选择合适的线程组大小。
Shader Pass和Compute Shader各有优势,选择哪一种方法
首先取决于具体的需求和硬件环境。
其次取决于数据类型以及处理方式。要考虑数据怎么去流转
3.6、Sea wave
上面的Shader 争议太多,现在我们来讨论CPU 和 GPU,这部分倒是没啥争议,让灵活的CPU体验一下,什么叫一力破万法
举一个例子,我们希望学生方阵,每个人往前一步,CPU的话,我们要怎么做?我们只能利用for循环,而且得等上一个人走一步以后,下一个人才能知道怎么做,所以我们的**时间复杂度是O(n)**这种就像报数,得一个一个来,报完数军训都晒了半个小时太阳了
TArray<int32> studentArray;
for (int32 i = 0; i < studentArray.Num(); i++)
{
int32 student = studentArray[i];
UE_LOG(LogTemp, Warning, TEXT("报数: %d "), i);
}
所以教官会准备一个哨子 Dispatch ,吹一下大家就往前一步,不用担心后面的同学听不见,哨子很大声。如果非要犟说学生很多,后面就是听不到,我们就规定学生方阵为 32 * 32 。每个学生口渴了,需要数据了,就去方阵放矿泉水的地方(共享内存)去获取数据
我们可以安排学生做什么?打少林拳!!!
但是打少林拳,就像GPU Skin,都是一样的动作,不好看。因为我们可以利用图案方阵,摆个大海浪,先看看效果
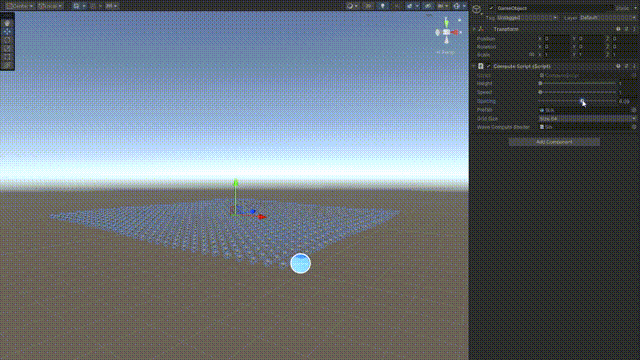
我们很简单,每个人是这样的行动,让学生们按照sin曲线去上下起伏就行了不要跑动
我们也可以设置一个间距去让学生跑动,这部分我就在C#里面实现,可以看看C#和Computer Shader 实现的差异性,全部放computer Shader 里面更好
Computer Shader 部分,让学生根据自己的位置以及时间、高度比和速度,去移动调整自己的高度,就不要跑动了
#pragma kernel CSMain
// 存储位置的结构化缓冲区
RWStructuredBuffer<float3> positions;
// 当前的时间,用于动画
float time;
// 网格的大小
int gridSize;
// 高度
int height;
//速度
int speed;
[numthreads(8, 8, 1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
int index = id.x + id.y * gridSize;
if (index >= gridSize * gridSize)
return;
// 获取当前物体的位置
float3 position = positions[index];
// 根据时间和位置应用sin波动到Y轴
position.y = sin(position.x + position.z + time * speed) * height;
// 将更新后的位置写回缓冲区
positions[index] = position;
}
所以computer Shader只需要根据时间,速度,高度比,去调整自己的高度就好了
C#也很简单,将自己的位置和相关信息传给computer shader,然后再读取取到的位置值,其实内容很简单
void UpdateWave()
{
int size = (int)gridSize;
waveComputeShader.SetFloat("time", Time.time);
waveComputeShader.SetFloat("height", height);
waveComputeShader.SetFloat("speed", height);
// 将位置数据传递给Compute Buffer positionBuffer.SetData(positions);
// 绑定缓冲区到Compute Shader waveComputeShader.SetBuffer(0, "positions", positionBuffer);
waveComputeShader.Dispatch(0, size / 8, size / 8, 1);
// 从Compute Buffer中获取更新后的位置信息 positionBuffer.GetData(positions);
// 更新实例化的物体的位置 for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
int index = i * size + j;
Vector3 newPosition = new Vector3(positions[index].x, positions[index].y, positions[index].z);
instances[i, j].transform.position = newPosition;
}
}
}
完整的C#代码如下
using UnityEngine;
public class ComputeScript : MonoBehaviour
{
// 用于控制网格大小的枚举 public enum GridSize
{
Size64 = 32,
Size256 = 64,
Size512 = 256,
Size1024 = 512
}
[Range(1,10)]
public int height;
[Range(1,10)]
public int speed;
[Range(1.0f, 10.0f)]
public float spacing = 6.0f;
public GameObject prefab;
public GridSize gridSize = GridSize.Size64;
public ComputeShader waveComputeShader;
private GameObject[,] instances;
// 用于存储位置的缓冲区 private ComputeBuffer positionBuffer;
// 用于保存所有物体位置的数组 private Vector3[] positions;
void Start()
{
SpawnGrid();
InitComputeShader();
}
void Update()
{
UpdateGridSpacing(); // 更新物体间的间距
UpdateWave(); // 更新Y轴波动 }
void UpdateGridSpacing()
{
if (instances == null)
{
return;
}
int size = (int)gridSize; // 将枚举值转换为int,获取当前的网格大小
// 计算中心点
Vector3 center = transform.position;
for (int x = 0; x < size; x++)
{
for (int z = 0; z < size; z++)
{
if (instances[x, z] != null)
{
// 计算新的位置
Vector3 position = center + new Vector3((x - size / 2) * spacing, 0, (z - size / 2) * spacing);
// 更新 `positions` 数组中的位置,以适应 ComputeShader 的使用
positions[x * size + z] = new Vector3(position.x, position.y, position.z);
// 更新物体的位置
instances[x, z].transform.position = position;
}
}
}
}
void SpawnGrid()
{
if (prefab == null)
{
Debug.LogError("Prefab is not assigned."); // 如果没有分配预制件,输出错误信息 return;
}
int size = (int)gridSize;
instances = new GameObject[size, size];
positions = new Vector3[size * size];
// 计算网格中心点
Vector3 center = transform.position;
for (int x = 0; x < size; x++)
{
for (int z = 0; z < size; z++)
{
// 计算每个物体的位置
Vector3 position = center + new Vector3((x - size / 2) * spacing, 0, (z - size / 2) * spacing);
positions[x * size + z] = new Vector3(position.x, position.y, position.z); // 存储位置
GameObject instance = Instantiate(prefab, position, Quaternion.identity);
instance.transform.parent = transform;
instances[x, z] = instance;
}
}
}
void InitComputeShader()
{
int size = (int)gridSize;
// 初始化用于存储位置的Compute Buffer
positionBuffer = new ComputeBuffer(size * size, sizeof(float) * 3);
waveComputeShader.SetInt("gridSize", size); // 将网格大小传递给Compute Shader }
void UpdateWave()
{
int size = (int)gridSize;
waveComputeShader.SetFloat("time", Time.time);
waveComputeShader.SetFloat("height", height);
waveComputeShader.SetFloat("speed", height);
// 将位置数据传递给Compute Buffer
positionBuffer.SetData(positions);
// 绑定缓冲区到Compute Shader
waveComputeShader.SetBuffer(0, "positions", positionBuffer);
waveComputeShader.Dispatch(0, size / 8, size / 8, 1);
// 从Compute Buffer中获取更新后的位置信息
positionBuffer.GetData(positions);
// 更新实例化的物体的位置
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
int index = i * size + j;
Vector3 newPosition = new Vector3(positions[index].x, positions[index].y, positions[index].z);
instances[i, j].transform.position = newPosition;
}
}
}
void OnDestroy()
{
// 当脚本销毁时,释放Compute Buffer
if (positionBuffer != null)
{
positionBuffer.Release();
}
}
}
3.7、UE
这里我们实例是个Cube就够了,不用弄太多
// 创建10个Cube实例for (int i = 0; i < 10; i++)
{
// 创建一个新的Cube实例
UStaticMeshComponent* Cube = CreateDefaultSubobject<UStaticMeshComponent>(TEXT("Cube" + FString::FromInt(i)));
// 设置Cube的位置
Cube->SetRelativeLocation(FVector(i * 100.0f, 0.0f, 0.0f));
// 添加Cube到Actor
Cube->AttachToComponent(RootComponent, FAttachmentTransformRules::KeepRelativeTransform);
}
// 创建Compute Shader实例
TShaderMapRef<FMyComputeShader> ComputeShader(GetGlobalShaderMap(GMaxRHIFeatureLevel));
// 设置Shader参数
FRHICommandListImmediate& RHICmdList = GRHICommandList.GetImmediateCommandList();
ComputeShader->SetParameters(RHICmdList, ...);
// 运行ShaderDispatch
ComputeShader(RHICmdList, *ComputeShader, 1, 1, 1);
// 取消设置Shader参数
ComputeShader->UnsetParameters(RHICmdList);
UE 的Computer Shader 有些特殊,他需要两个文件C++代码和HLSL代码。C++代码用于定义Shader类和参数,HLSL代码用于实现实际的Shader逻辑
Unity是这样的,UE需要考虑的就多了
// MyComputeShader.h#pragma once
#include "GlobalShader.h"
#include "UniformBuffer.h"
#include "RHICommandList.h"
// 声明一个名为FMyComputeShader的Compute Shader类,继承自FGlobalShaderclass
FMyComputeShader : public FGlobalShader
{
DECLARE_SHADER_TYPE(FMyComputeShader, Global);
public:
FMyComputeShader() {}
explicit FMyComputeShader(const ShaderMetaType::CompiledShaderInitializerType& Initializer)
: FGlobalShader(Initializer)
{
// 在这里初始化Shader参数
CubePositionsBuffer.Bind(Initializer.ParameterMap, TEXT("CubePositionsBuffer"));
}
// Serialize方法用于绑定参数到Shader
virtual bool Serialize(FArchive& Ar) override
{
bool bShaderHasOutdatedParameters = FGlobalShader::Serialize(Ar);
Ar << CubePositionsBuffer;
return bShaderHasOutdatedParameters;
}
// SetParameters方法用于设置Shader参数
void SetParameters(FRHICommandList& RHICmdList, FUnorderedAccessViewRHIRef CubePositionsBufferUAV)
{
FRHIComputeShader* ShaderRHI = RHICmdList.GetBoundComputeShader();
SetUAVParameter(RHICmdList, ShaderRHI, CubePositionsBuffer, CubePositionsBufferUAV);
}
// UnsetParameters方法用于在Shader使用后取消设置参数
void UnsetParameters(FRHICommandList& RHICmdList)
{
FRHIComputeShader* ShaderRHI = RHICmdList.GetBoundComputeShader();
SetUAVParameter(RHICmdList, ShaderRHI, CubePositionsBuffer, FUnorderedAccessViewRHIRef());
}
private:
FShaderResourceParameter CubePositionsBuffer;
};
五、Editor
UE的编辑器,由于他自带的功能,以及蓝图,其实一些常见的编辑器功能做出来其实很方便。
UE是这样的,Unity需要考虑的就多了
5.1 Texture
如何将多个贴图的特定通道输出到一张图上,有很多做法
常见的是利用Shader,采样多张贴图,随后分别填入Color 随后输出
float4 baseMap_1 = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.uv);
float4 baseMap_2 = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.uv);
float4 baseMap_3 = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.uv);
float4 baseMap_4 = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.uv);
return Color = float4(baseMap_1.r, baseMap_2.g,baseMap_3.b,baseMap_4.A);
这样的话还得利用脚本,去实时监测材质球是否存在,然后利用Graphics去绘制
Material material = /* 你的材质 */;
Texture2D sourceTexture = /* 源纹理 */;
RenderTexture destinationTexture = /* 目标纹理 */;
// 使用材质将源纹理复制到目标纹理
Graphics.Blit(sourceTexture, destinationTexture, material);
随后还得RenderTexture 转化为Texture2D
RenderTexture renderTexture = /* 你的RenderTexture */;
Texture2D texture = new Texture2D(renderTexture.width, renderTexture.height);
// 设置当前的RenderTextureRenderTexture
currentActiveRT = RenderTexture.active;
RenderTexture.active = renderTexture;
// 从RenderTexture中读取像素到Texture2D中
texture.ReadPixels(new Rect(0, 0, renderTexture.width, renderTexture.height), 0, 0);
texture.Apply();
// 恢复之前的RenderTextureRender
Texture.active = currentActiveRT;
C# SAMPLE
如果是利用C#去采样的话,但是由于利用遍历,在项目中许多窗口同时开启的情况下,其实也会有些卡顿,不止是玩家对游戏的帧率很敏感,开发者对于editor的帧率也很敏感(如 Graph View类)
Texture2D textureR = /* 红色通道的贴图 */;
Texture2D textureG = /* 绿色通道的贴图 */;
Texture2D textureB = /* 蓝色通道的贴图 */;
Texture2D textureA = /* alpha通道的贴图 */;
int width = textureR.width;
int height = textureR.height;
// 创建新的贴图Texture2D
newTexture = new Texture2D(width, height);
// 遍历每个像素for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
// 从源贴图中采样颜色
float r = textureR.GetPixel(x, y).r;
float g = textureG.GetPixel(x, y).g;
float b = textureB.GetPixel(x, y).b;
float a = textureA.GetPixel(x, y).a;
// 设置新贴图的像素颜色
newTexture.SetPixel(x, y, new Color(r, g, b, a));
}
}
// 应用更改newTexture.Apply();
newTexture.Apply();
5. 2 Shader
如果是利用Computer Shader 的话,那么可以利用GPU的高并行快速绘制,也不会有卡顿现象的发生。
#pragma kernel CombineTextures
// 输入纹理
Texture2D<float4> TextureR;
Texture2D<float4> TextureG;
Texture2D<float4> TextureB;
Texture2D<float4> TextureA;
// 输出纹理
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CombineTextures (uint3 id : SV_DispatchThreadID)
{
// 从输入纹理中采样颜色
float r = TextureR[id.xy].r;
float g = TextureG[id.xy].g;
float b = TextureB[id.xy].b;
float a = TextureA[id.xy].a;
// 将采样的颜色写入到输出纹理
Result[id.xy] = float4(r, g, b, a);
}
Computer Shader 其实对于这种贴图类的工具效率提升是巨大