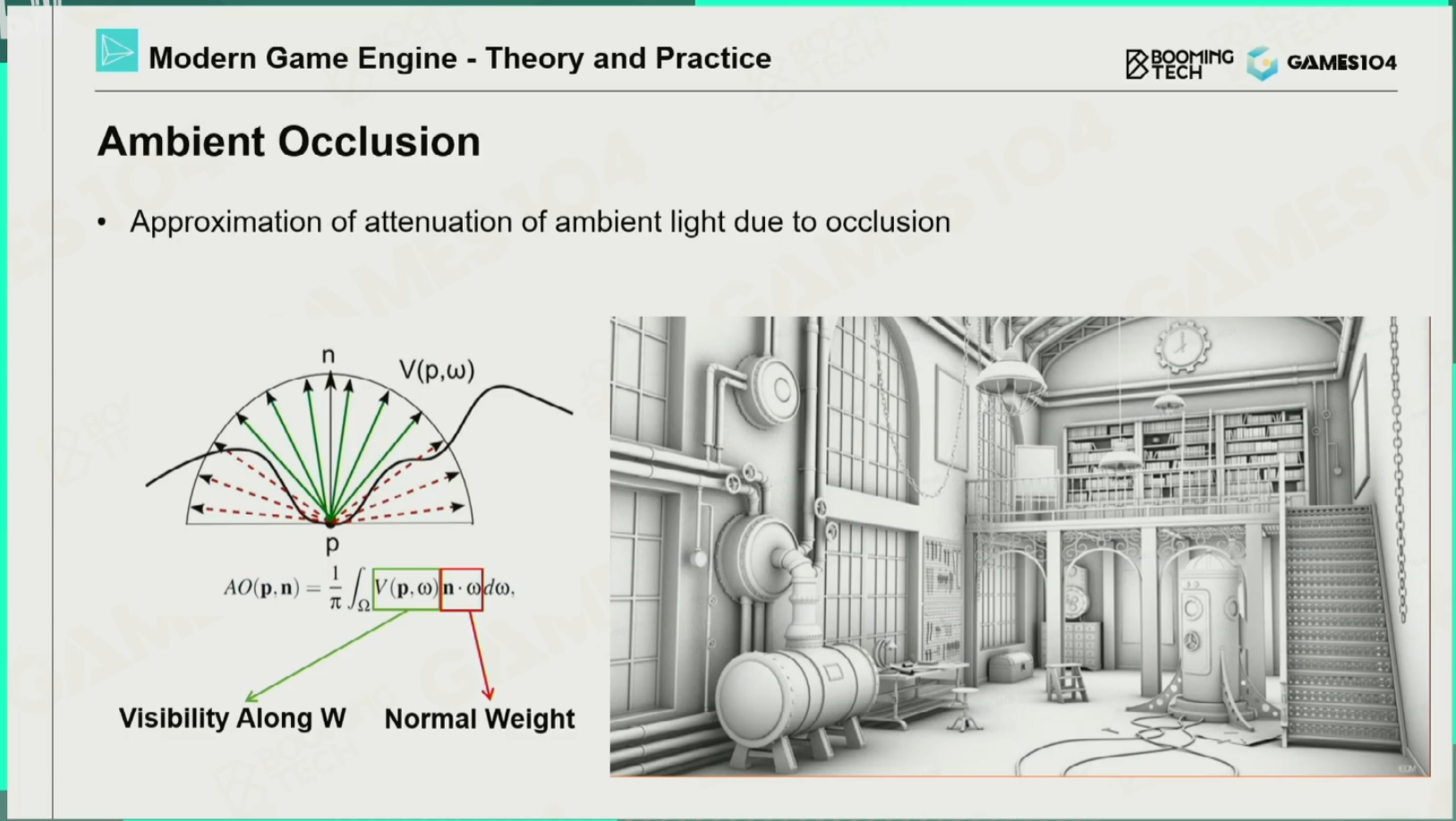
环境光遮蔽AO
数学原理:对表面每一个点在其可看见的正半球面只有部分能看见天光,其余的被物体遮挡

通过Ray Tracing在建模软件内离线计算到贴图中;空间换时间。
缺点:计算昂贵;只能用于静态模型
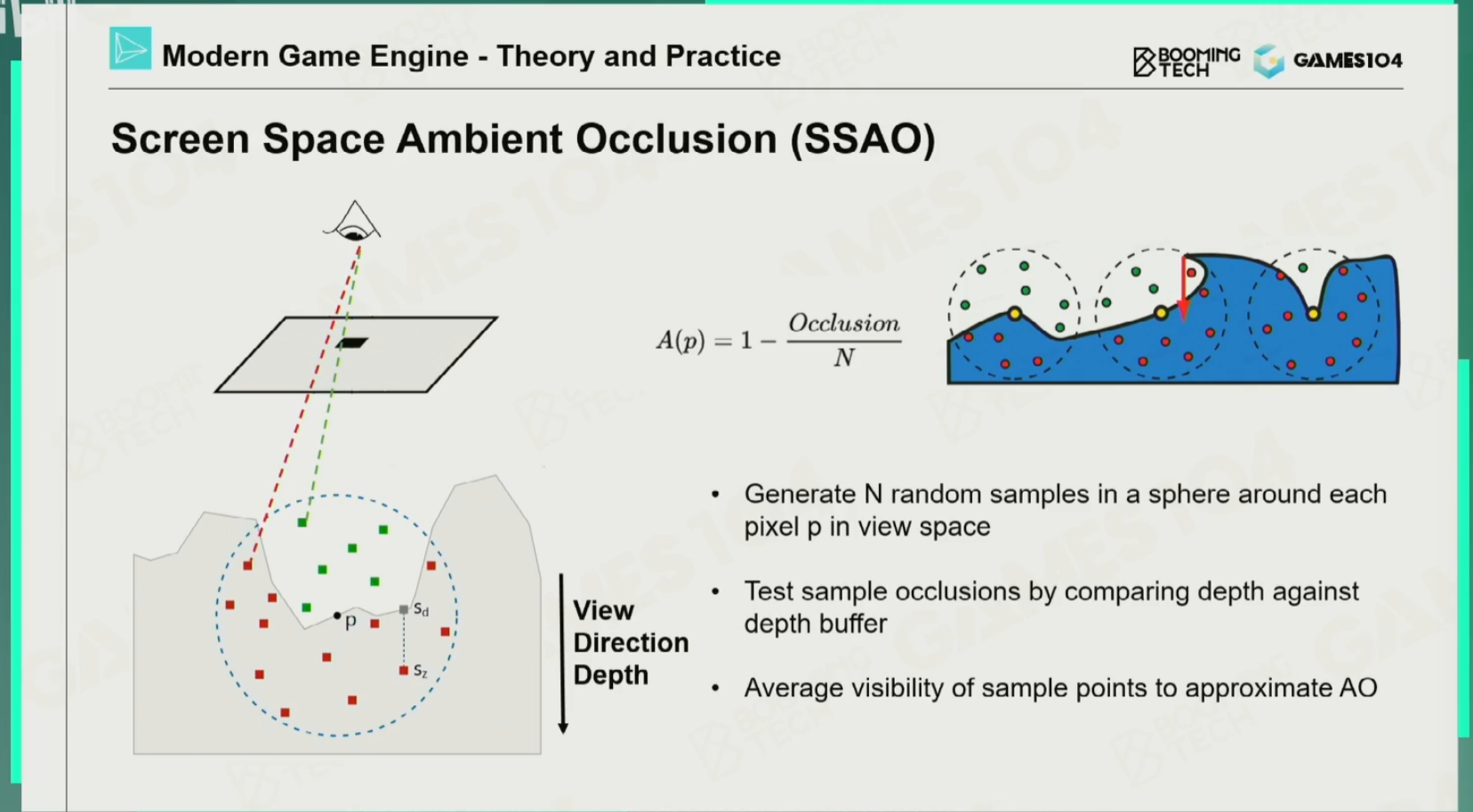
屏幕空间环境光遮蔽(SSAO)

思想:从相机发射射线寻找交点,在交点处以一个半径均匀撒点,再用相机去投射采样点就能获得深度信息,再拿这个深度信息和Z-buffer比较,如果深度更小,说明该采样点能看见光;如果深度更大,说明该采样点就被挡住了。
缺点:环境光的计算应该是半球面,均匀撒点就会有50%的概率撒在错误的一半。
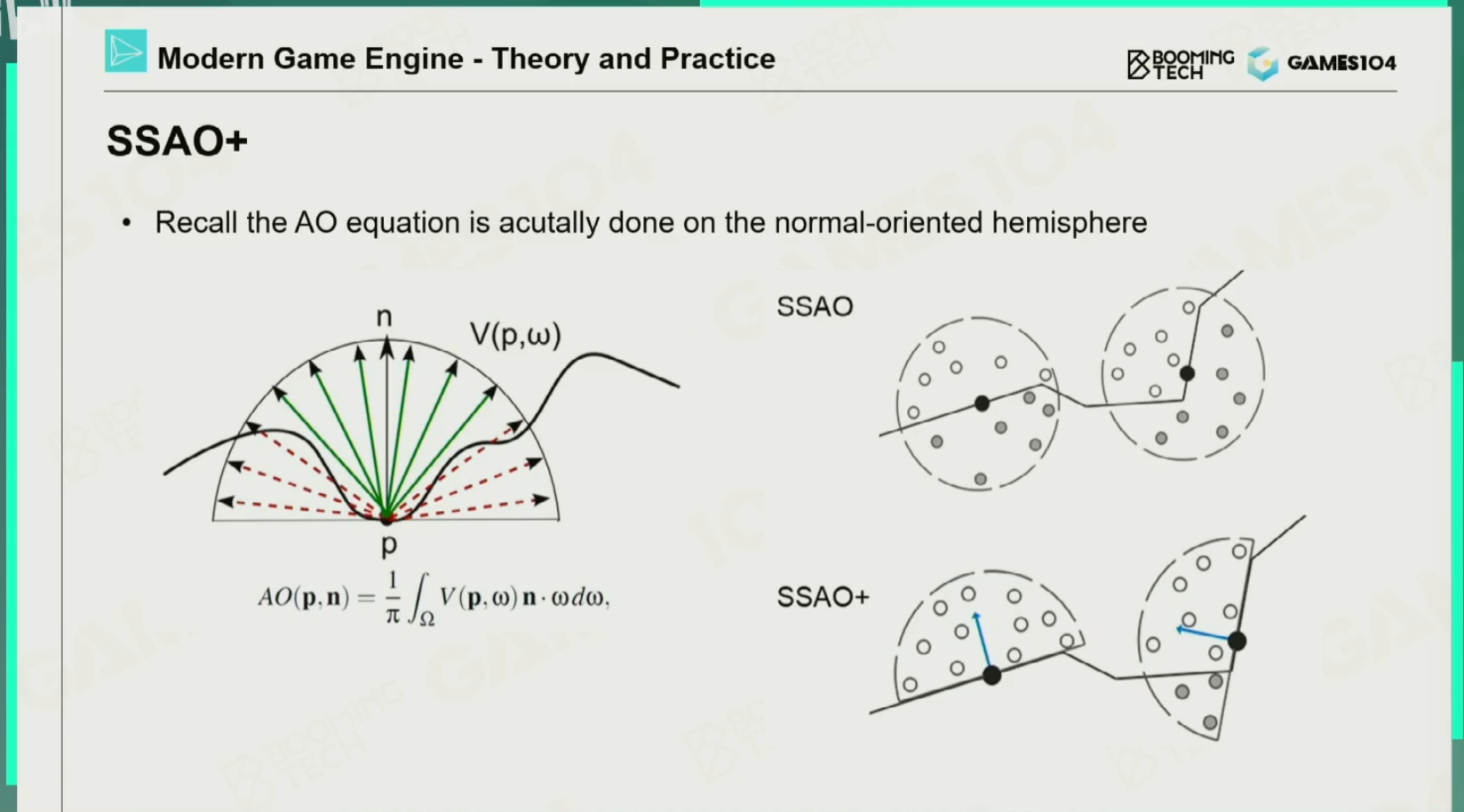
SSAO+

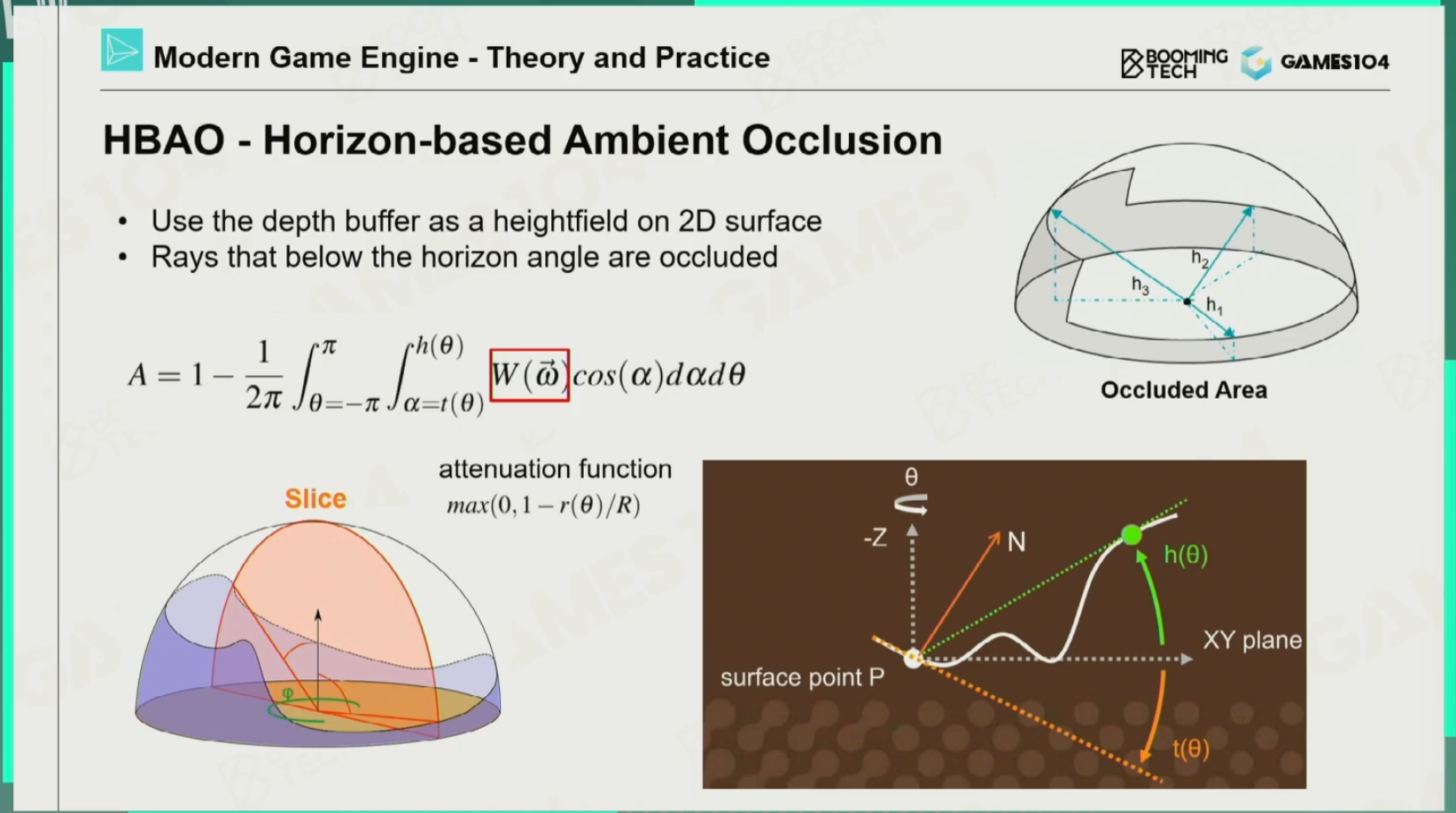
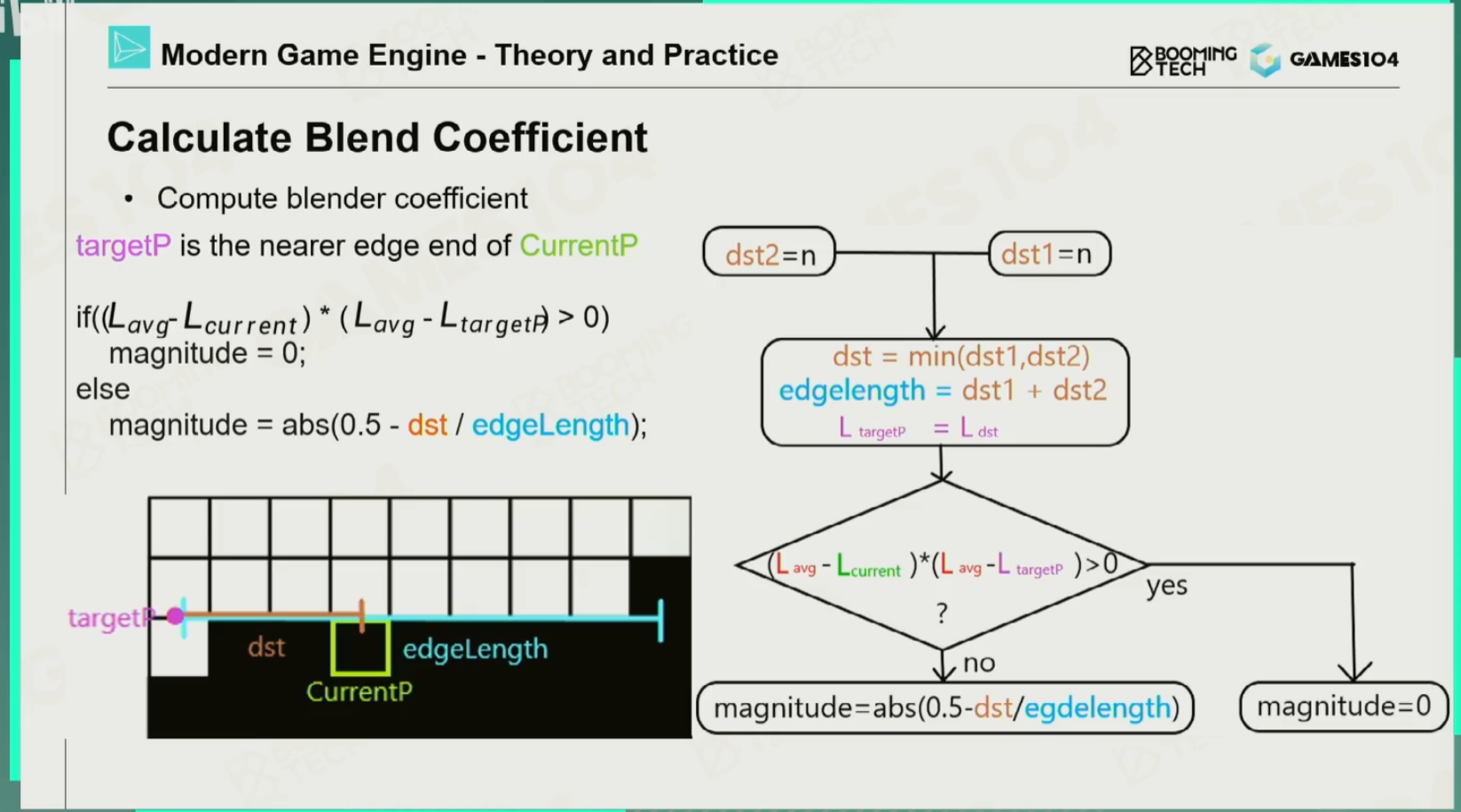
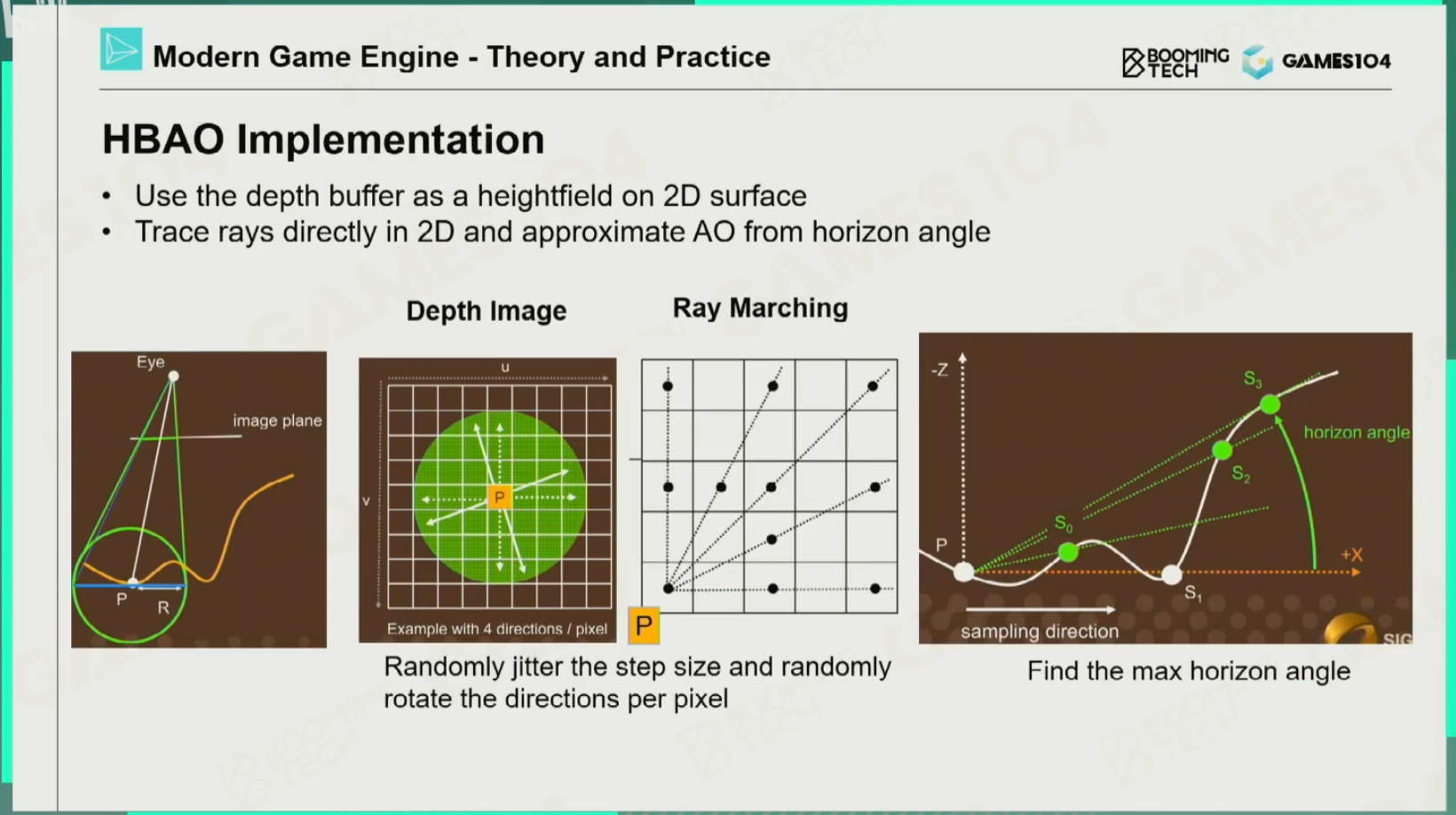
HBAO
思想:通过Ray Marching光线检测判断光线所能接收到的最大的仰角范围,就能得到有多少面积的天顶是可见的,有多少面积的天顶是被遮挡的。再加入一个衰减方程,如果距离太远,就对AO没什么变化。

缺点:如果一个面朝向正上方,那么从天顶射来的光和侧面射来的光明显应该有所区别。
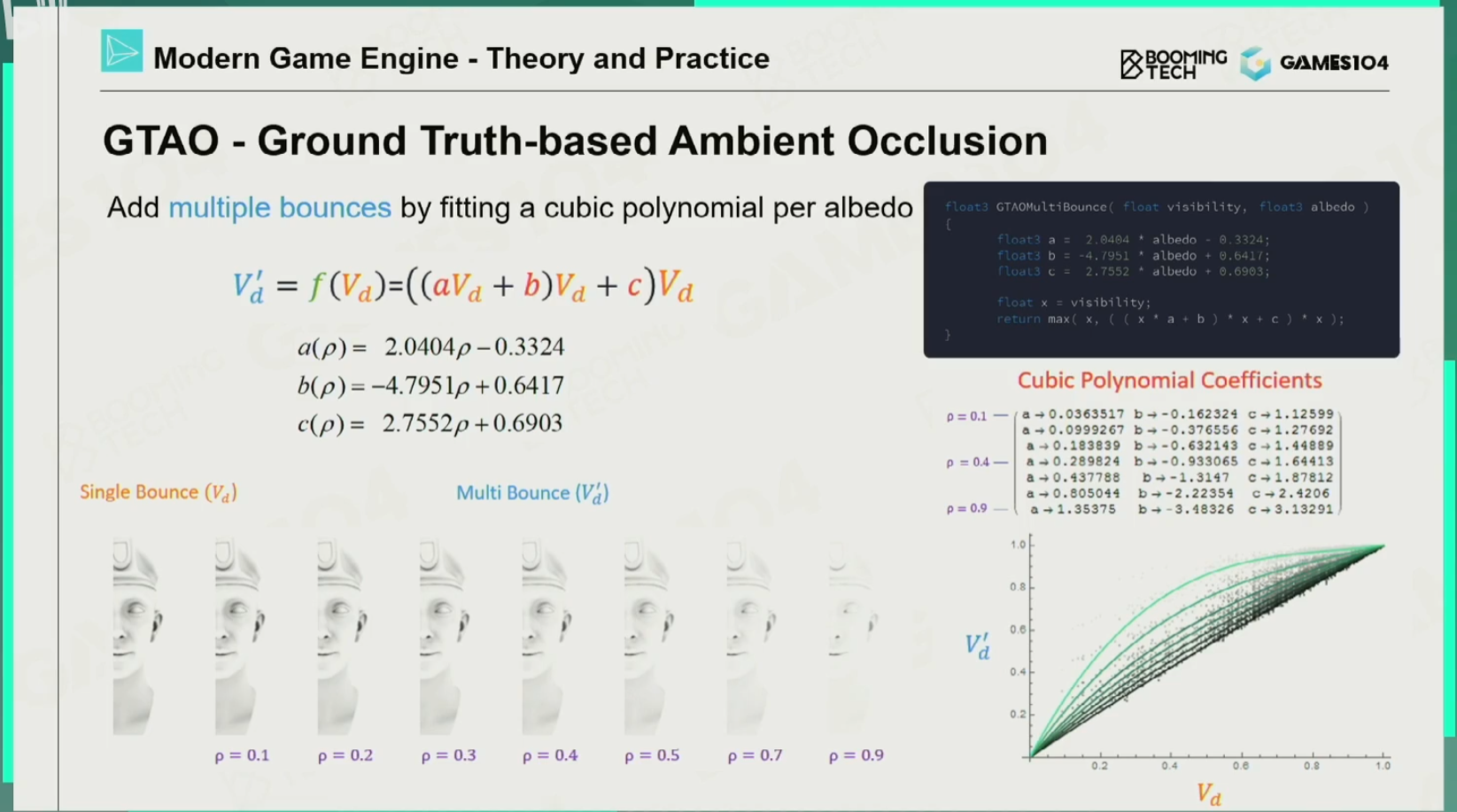
真实情况环境光遮蔽GTAO
思想:GTAO引入了cos函数,删除了衰减函数,并且增加了多次反弹。


思想:通过强大的GPU能实时发射射线检测可见性。
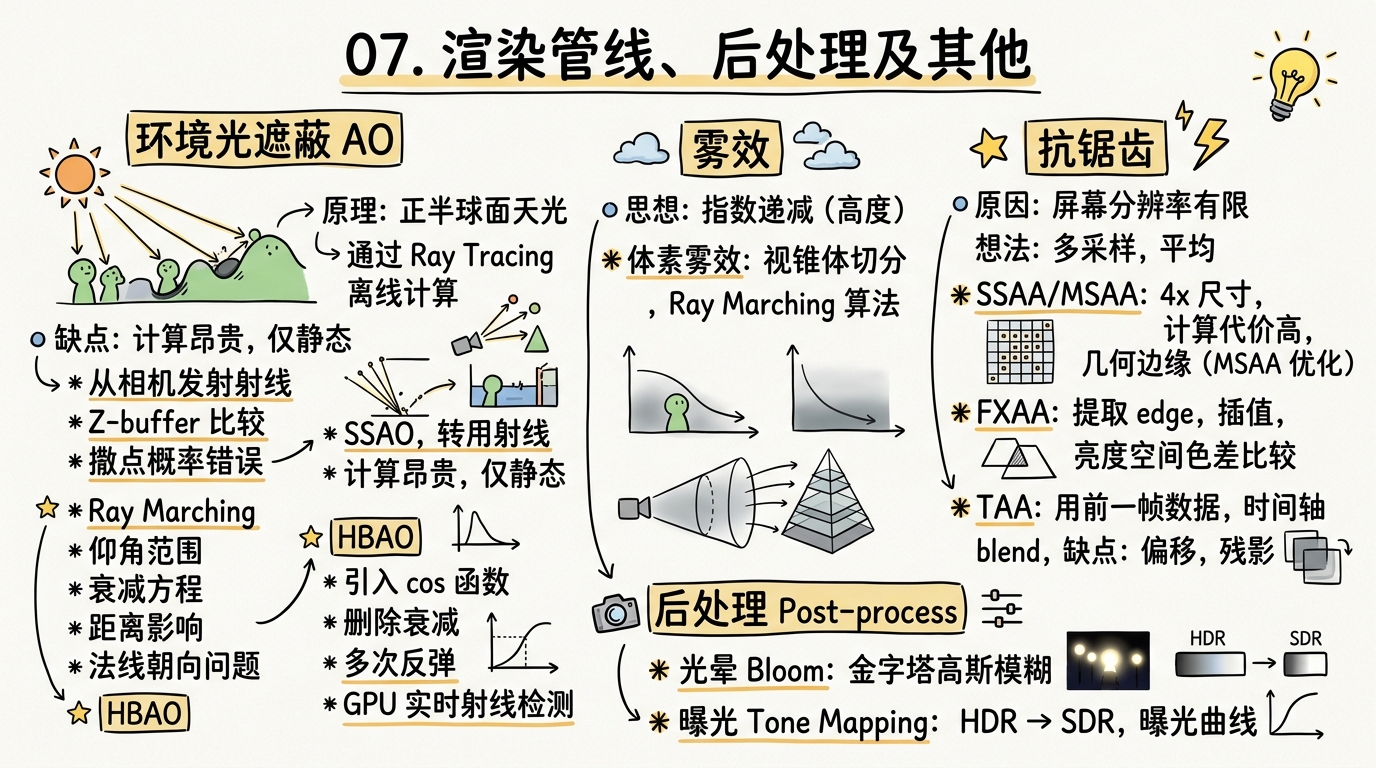
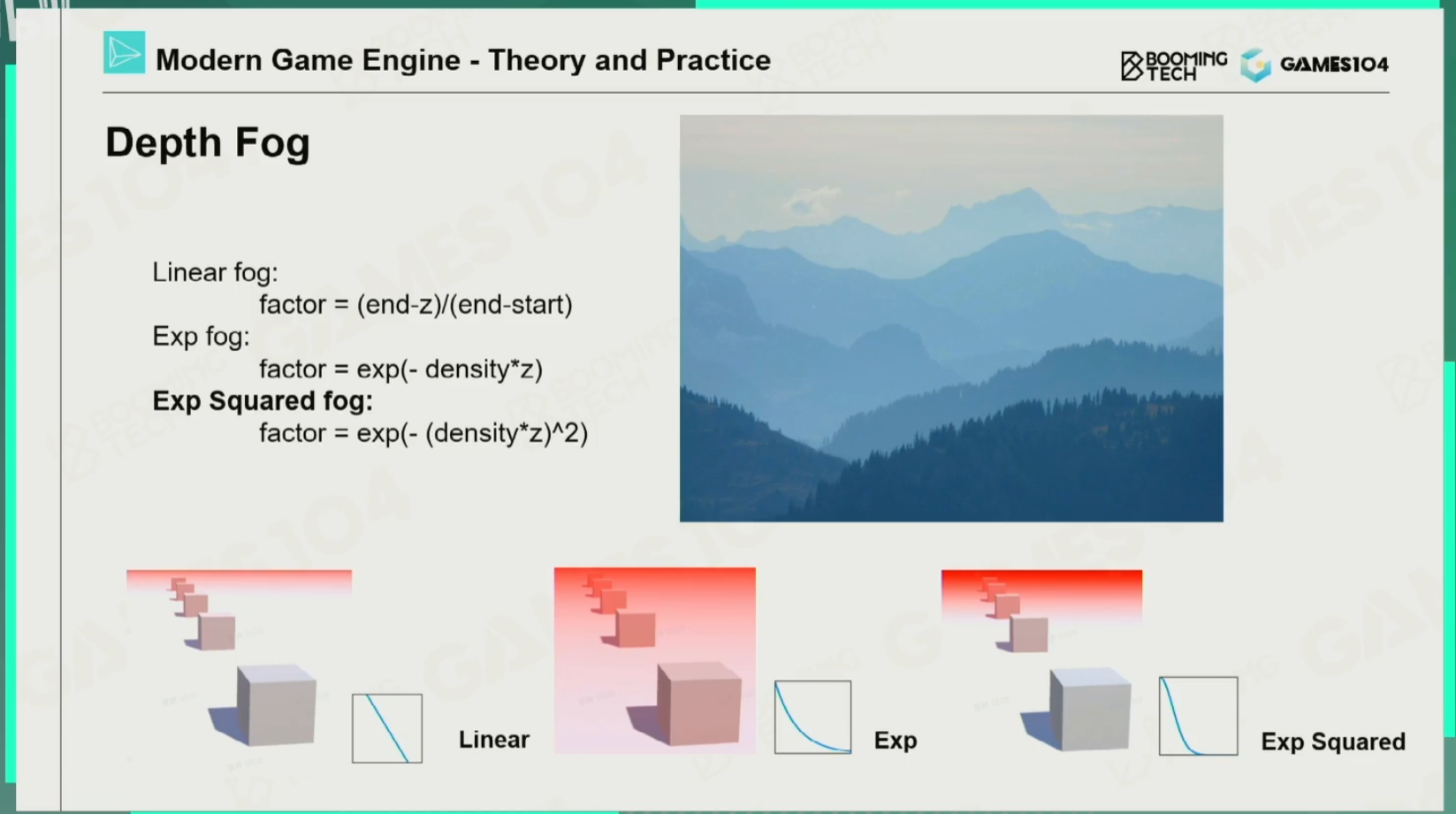
雾效

思想:当高度低于设定值时,雾效的值都是最大的那个;当高度高于设定值时,雾效的值就是一个指数递减的值。
体素雾效

思想:根据摄像机视锥体,离近平面越近切分越密。然后在视锥体内再运用Ray Marching等算法实现(与算大气效果类似)。
抗锯齿


图片走样的原因:真实世界的采样率是无限的,而屏幕的分辨率是有限的。
思想:我们知道频幕上像素的采样是不充分的,所以我们就多采样几次,把采样的值再平均。
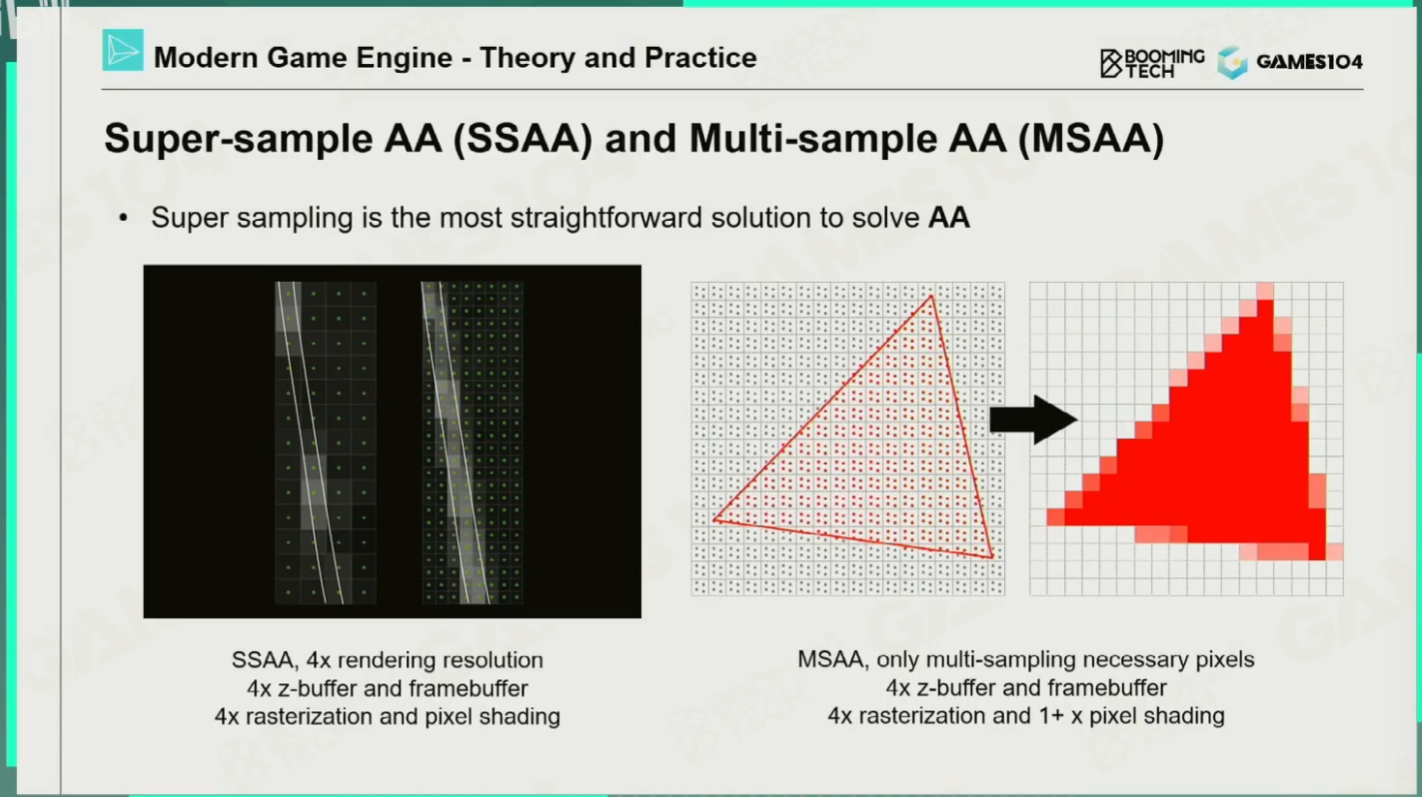
超采样(SSAA)&多采样(MSAA)
SSAA:把所有尺寸double一下再降频为最终的结果。缺点:付出了4x的计算代价。
锯齿产生最多的地方在几何的边缘,超采样中的大部分点其实不需要超采样,因为很多点都在几何的内部,真正有问题的是那些只占据一小部分的像素。
MSAA:虽然对空间依然是4x的采样,但做shading的时候,如果这四个像素都落在同一个像素上,那就只shaing一次。如果不在一个像素上,那就都shading好,再根据占据比例算一个平均值。
快速近似抗锯齿(FXAA)

想法:提取图片的edge,只在edge的地方用插值的方法。对一个像素点采样它上下左右的像素做平均,如果大于某个阈值,那么就标记为边界。阈值怎么获得:把图片转化为亮度空间在对上下左右比较色差。

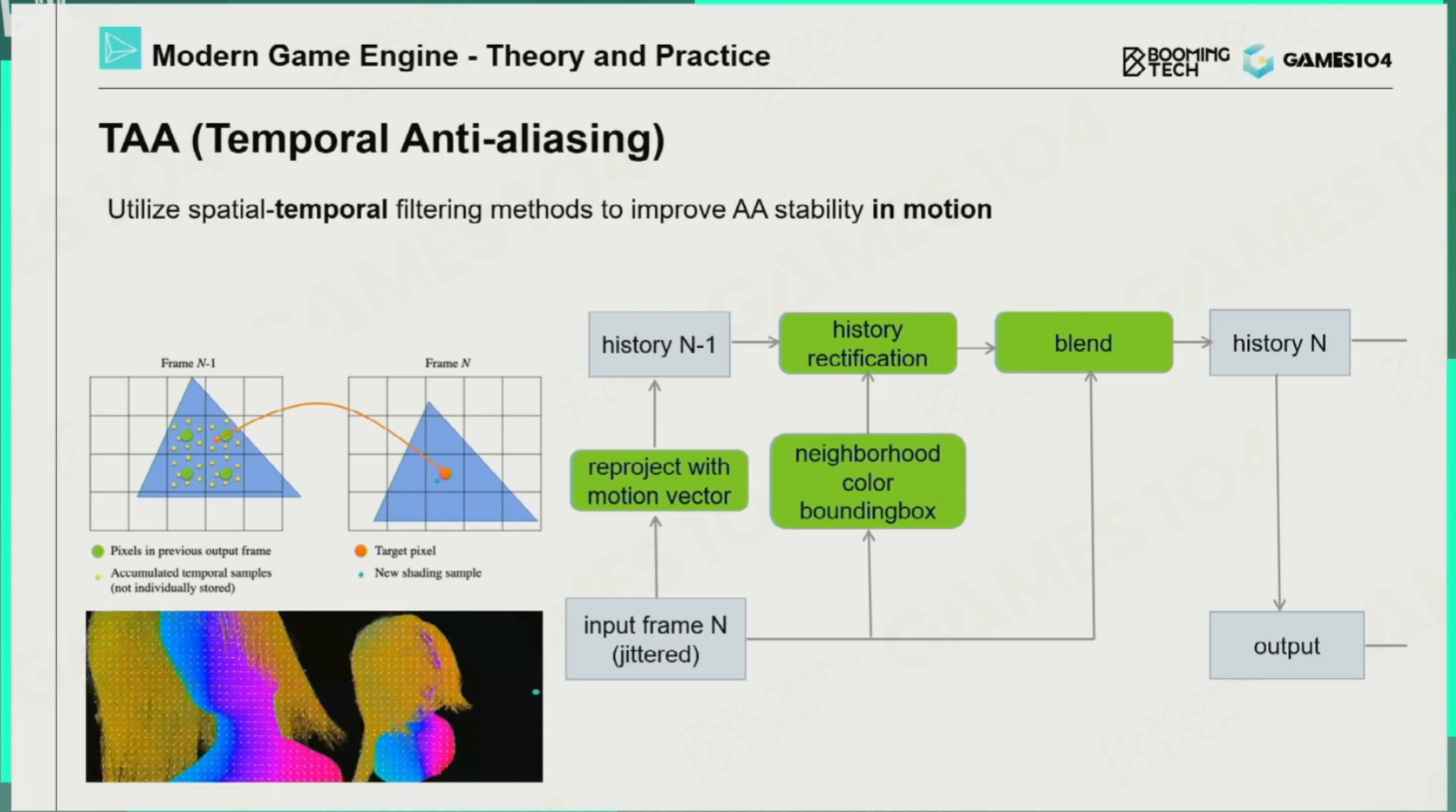
时序抗锯齿TAA
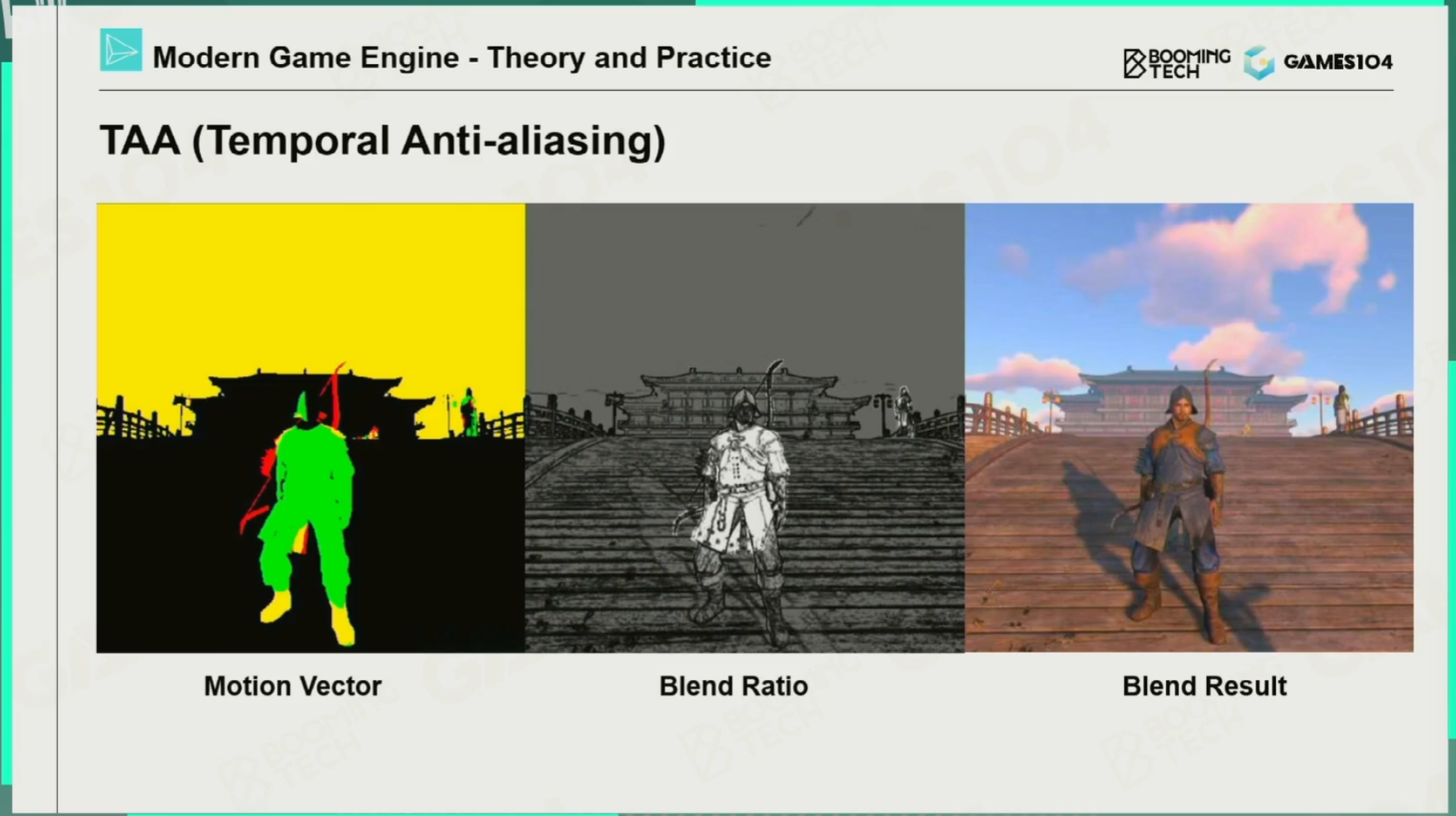
思想:这一帧的计算用前一帧的数据,在时间轴上找数据


TAA缺点:看见On/Off之间有偏移了吗?因为TAA是和上一帧做的blend,所以会有一些offset,做不好时也会出现一些残影。
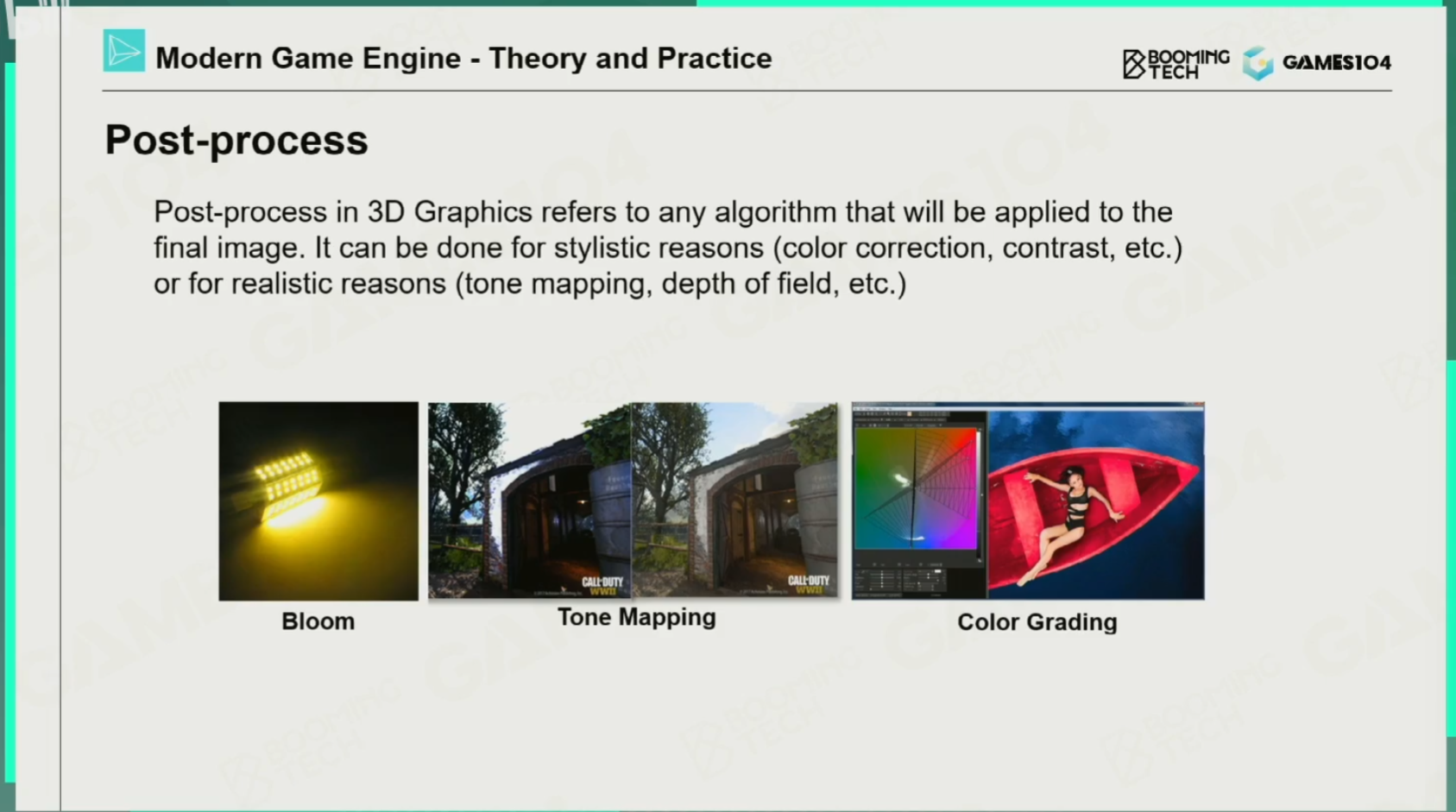
后处理Post-process
光晕Bloom
光晕的物理基础:现实世界的透镜永远不可能完美聚焦;即使是完美的透镜也会产生光圈。
如何做光晕
金字塔高斯模糊
曝光
现代游戏都会制作HDR的内容,但是许多用户没有支持HDR的硬件,所以要通过一个曝光曲线来控制让SDR的色彩显示HDR的色彩。
优势:可以经过在pipeline后端的调整统一HDR/SDR的颜色显示;对美术团队的干扰很小。
调色
LUT可以将原有颜色的数据映射到一个新的颜色;可以理解为一种应用于图像或镜头的预设。
渲染管线
这么多的算法必须要有一套规则制定顺序,谁先谁后。
前向渲染Foward Rendering
透明的物质一定是在不透明物质之后渲染,并且要规定不透明物质的排序;首先绘制离相机选的,再绘制近的。
缺点:现代游戏场景光极其复杂
延迟渲染 Deferred Rendering
思想:把所有的物体先渲染一遍,但先不计算和光的关系,把Albedo、Specular、Normal、Depth等先存在G-Buffer中,这样模型就可以先单独算光的部分了。
优势:计算高度一致;照明只计算可见光;G-Buffer数据可用于后处理。
缺点:计算很费内存和带宽;不支持半透明物体;对MSAA抗锯齿不友好。
Tile-based Rendering
思想:把画面切成一小块一小块里的,只把一小块的结果存在FrameBuffer里,而不需要一个巨大的G-Buffer,减少读写的压力。
优势:可以得到光照在多少Tiles内计算,减少不需要的计算范围,得以更加高效。
Forward+(Tile-based Forward) Rendering
Cluster-based Rendering 集群渲染
遍历每个Tiles对光线的可见性进行计算
最新的技术 Visibility Buffer
之前讲述的延迟渲染的本质上是把大量的材质信息写到G-Buffer中;随着现代硬件的发展,已经可以把几何信息和材质信息剥离开来。在一个FrameBuffer中存储像素属于哪个几何体ID,可以反向去查某个三角面应该用什么材质;就能在后续过程中直接进行Shading。
曾经在游戏中普遍认为材质很复杂,而现如今几何的复杂程度很可能超过材质。
在G-Buffer中制作Shading时去查TextureSampler的效率非常低,现在在Visibility Buffer取到值之后直接去查VB和ID,效率极高。
G-Buffer中存储的是材质的全属性;Visibility Buffer中存的是几何的全属性。不需要的材质类型都去除掉了。
Frame Graph
真实的算法管线
脚本渲染管线Scriptable Render Pipeline(SRP)
思想:把pipeline中的东西变成一个个模块,把计算和资源的依赖用一个有向无环图Directed Acyclic Graph(DAG)表达出来
V-sync & G-sync
V-sync
原因:GPU帧率有时候是不稳定的,但显示器帧率是一致的。
思路:G-Buffer必须全部渲染完才输出到屏幕。